LLM
Why LLM?
- 我最早了解NLP是在2019年大一的时候,当时是一个机缘巧合认识的老乡朋友给我介绍的一本书,吴军老师的《浪潮之巅》。吴军老师当时应该是在Google做NLP和搜索引擎的研究,所以在书中,吴军老师用了大量的NLP领域的相关内容来进行举例,这让我第一次知道了NLP这个领域。但那个时候我甚至并未接触到编程这个概念,所以当时的我是一知半解,不太理解这个NLP现在发展怎么样?后面又会怎么发展?
- 我们都知道OpenAI的ChatGPT掀起了这波LLM的巨大浪潮,OpenAI这个公司在我17、18年上高中的时候就知道了,那时的我很迷恋马斯克,看了好几本他的传记,因此当时也对OpenAI在做的事情也大概了解一下。后面OpenAI做的游戏AI在DOTA2中战胜了人类玩家,陆续发布了GPT-1,GPT-2,其实我都见证了那个时刻。当然作为“填鸭教育”的高中生,还是同样的问题,我并不能理解AI是什么?AI发展到什么程度了?AI后续又会发展到什么程度?
- 2021年,我开始接触深度学习,这时候CV的声量是比NLP要大很多的。
- 2022年,我选择后面要走深度学习的这条路,我对这个方向保有了很大的期待,我觉得这件事很酷。
- 在2022年的那个时候,我对深度学习方向的选择是在CV和语音方向的,最后我选择了CV,因为当时的我觉得这是一个更加热门的方向,可以做的东西比较多。
- 2022年11月30日,ChatGPT震撼登场!我应该是在12月份才知道的这个消息,但我当时其实并未有什么波澜,因为我还理解不了这可能意味着什么。
- 因为处于CV的圈子中,甚至因为一些原因这个圈子也被限制的死死的,所以我并没有接触到身边的人有在做LLM的,我一直在为自己在CV上面有跑出来了一个“XX”模型在沾沾自喜,目光短浅,视野不够开阔。
- 现在是2025年,甚至马上要到2026年,我想在这个时间点去了解一下LLM,其实当前的LLM并不是仅限于了NLP了,这是一项复杂的系统工程。所以尽管后面要做的东西可能并不是LLM,但我认为我应该要去了解一下这项技术背后的东西,毕竟这是每天都在用的东西,与我息息相关。
- 大概是春节期间的DeepSeek-R1发布之后吧,想要了解LLM背后技术的心开始躁动,但现实很难如意,各种鸡毛蒜皮使我应付不过来。但不管怎么样,我都想要花一些时间来学习一下LLM,要不然我就OUT了!
Links
- ZJU-LLMs/Foundations-of-LLMs
- ChatGPT的朋友们:大语言模型经典论文一次读到吐: https://zhuanlan.zhihu.com/p/620360553
- 一文看完多模态:从视觉表征到多模态大模型:https://zhuanlan.zhihu.com/p/684472814
- Google与OpenAI在LLM领域的发展时间线: https://hub.baai.ac.cn/view/23989
- 大语言模型简史. 2025年初,随着中国推出的开创性、高性价比的大型语言模型(LLM) — —… | by LM Po | Medium
大小模型端云协同
Datawhale LLM
- happy-llm( https://github.com/datawhalechina/happy-llm ):从零开始讲解 LLM 原理、并引导学习者亲手搭建、训练 LLM 的完整教程。
- self-llm(开源大模型食用指南:https://github.com/datawhalechina/self-llm ):为开发者提供一站式开源 LLM 部署、推理、微调的使用教程。
- llm-universe(动手学大模型应用开发:https://github.com/datawhalechina/llm-universe ): 指导开发者从零开始搭建自己的 LLM 应用。
- datawhalechina/tiny-universe: 《大模型白盒子构建指南》:一个全手搓的Tiny-Universe
Happy-LLM
0. 前言
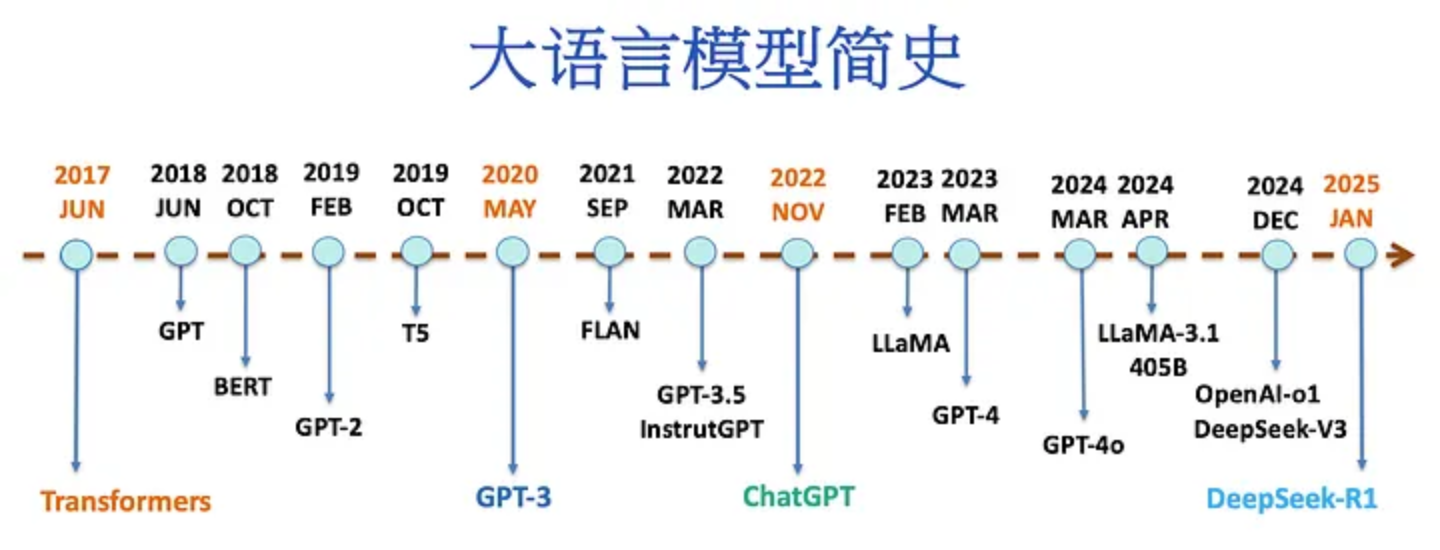
- 2023年, LLM;
- 自然语言处理(Natural Language Process,NLP);
- 预训练语言模型(Pretrain Language Model,PLM);
- 大语言模型(Large Language Model,LLM);
- 符号主义阶段、统计学习阶段、深度学习阶段、预训练模型阶段、大模型阶段;
- 注意力机制为模型架构,通过预训练-微调的阶段思想通过在海量无监督文本上进行自监督预训练,实现了强大的自然语言理解能力。
- 扩大模型参数、预训练数据规模;指令微调;人类反馈强化学习;
- 涌现能力;
- 上下文学习能力、指令理解能力和文本生成能力;
1. NLP
- NLP 是 一种让计算机理解、解释和生成人类语言的技术。
- NLP of Deep Learning: 循环神经网络(Recurrent Neural Network,RNN)、长短时记忆网络(Long Short-Term Memory,LSTM)和注意力机制
- 2013年,Word2Vec模型; 2018年,BERT模型; Transformer-based Models
- Word2Vec
- ELMo(Embeddings from Language Models)
2. Transformer架构
- NLP 任务所需要处理的文本往往是序列;RNN 以及 RNN 的衍生架构 LSTM
- 并行能力限制
- 长距离相关信息
- 注意力机制最先源于计算机视觉领域,其核心思想为当我们关注一张图片,我们往往无需看清楚全部内容而仅将注意力集中在重点部分即可。而在自然语言处理领域,我们往往也可以通过将重点注意力集中在一个或几个 token,从而取得更高效高质的计算效果。
- 注意力机制有三个核心变量:Query(查询值)、Key(键值)和 Value(真值)。
- 注意力机制的特点是通过计算 Query 与Key的相关性为真值加权求和,从而拟合序列中每个词同其他词的相关关系。
3. 预训练语言模型
- Encoder-Only: BERT
- Encoder-Decoder: T5
- Decoder-Only: GPT
3.1 Encoder-only PLM
- 海量无监督语料上进行预训练来获得通用的文本理解与生成能力,再在对应的下游任务上进行微调。
- 所谓微调,其实和训练时更新模型参数的策略一致,只不过在特定的任务、更少的训练数据、更小的 batch_size 上进行训练,更新参数的幅度更小。
- BERT衍生:RoBERTa(更大的BERT);ALBERT(更小的BERT)
3.2 Encoder-Decoder PLM
- T5
- T5模型的一个核心理念是“大一统思想”,即所有的 NLP 任务都可以统一为文本到文本的任务。
- 对于不同的NLP任务,每次输入前都会加上一个任务描述前缀,明确指定当前任务的类型。
3.3 Decoder-Only PLM
- 事实上,Decoder-Only 就是目前大火的 LLM 的基础架构,目前所有的 LLM 基本都是 Decoder-Only 模型(RWKV、Mamba 等非 Transformer 架构除外)。
- 引发 LLM 热潮的 ChatGPT,正是 Decoder-Only 系列的代表模型 GPT 系列模型的大成之作。
- 开源 LLM 基本架构的 LLaMA 模型,也正是在 GPT 的模型架构基础上优化发展而来。
为什么 GPT 叫 Decoder-Only?
GPT 之所以被冠以“解码器”之名,是因为它保留了原始 Transformer 解码器的关键特性: 因果(Causal)掩码。
- 决定性因素:因果掩码(Causal Masking)
Decoder-Only 的本质: 任何被称为 Decoder-Only 的模型,其自注意力层都使用了因果掩码(或称为前瞻掩码)。
- 作用: 强制模型在处理序列中的任何一个 Token 时,只能关注它之前(左侧)的 Token,而不能看到它之后(右侧/未来)的 Token。
- 目的: 这是为了模拟人类写字或说话的过程——预测下一个词是基于前面已经出现的所有词。这种机制使得模型具备自回归(Autoregressive)能力,能够进行文本生成。
Encoder-Only 的区别: 像 BERT 这样的 Encoder-Only 模型,其自注意力层是双向(Bidirectional)的,没有因果掩码。模型可以看到输入序列中的所有 Token,因此它擅长理解上下文,但无法自然地按顺序生成文本。
- 原始 Transformer Decoder 层的双注意力层设计,可以分解为:
- 带因果掩码的自注意力层(Self-Attention with Mask): 关注已生成(自身)的部分。
- 编码器-解码器注意力层(Encoder-Decoder Attention): 关注编码器的输出。
GPT 架构移除了第 2 层,因为它不再需要 Encoder 的输入。但它保留了第 1 层,正是这一层定义了其“解码器”的身份和生成功能。
Decoder-Only 与 Encoder-Only 的本质区别
| 特性 | Encoder-Only (BERT) | Decoder-Only (GPT, Llama) |
|---|---|---|
| 代表模型 | BERT、RoBERTa | GPT 系列、Llama、Claude |
| 注意力机制 | 双向(无掩码) | 单向/因果(带掩码) |
| 核心功能 | 理解(NLU):理解上下文、分类、抽取信息 | 生成(NLG):补全、续写、对话 |
| 预训练目标 | 遮蔽语言模型 (MLM):填空题 | 传统语言模型 (LM):预测下一个词 |
| 信息流向 | 整个序列信息可以完全流动 | 信息流向被严格限制为单向 |
BERT 是一个阅读理解器。它的目标是理解一整段话的意思,所以它必须能双向查看所有内容。
GPT 是一个作家/聊天机器人。它的目标是接续你已经写出的内容,所以它必须遵循因果关系,一个词一个词地生成,绝不能“偷看”到它还没有生成的部分。
架构上看起来相似,但注意力掩码这个微小的差异,决定了模型的功能和用途。
GPT
- GPT-1
- GPT-2, zero-shot(零样本学习)
- GPT-3, few-shot. few-shot 也被称为上下文学习(In-context Learning),即让模型从提供的上下文中的示例里学习问题的解决方法。
- 在 GPT 系列模型的基础上,通过引入预训练-指令微调-人类反馈强化学习的三阶段训练,OpenAI 发布了跨时代的 ChatGPT,引发了大模型的热潮。
LLaMA
- 开放权重LLMs
GLM
- ChatGLM-6B 是 GLM 系列的开山之作,也是 2023年国内最早的开源中文 LLM,也是最早提出不同于 GPT、LLaMA 的独特模型架构的 LLM。
- GLM(General Language Model,通用语言模型)。GLM 是一种结合了自编码思想和自回归思想的预训练方法。
- 所谓自编码思想,其实也就是 MLM 的任务学习思路,在输入文本中随机删除连续的 tokens,要求模型学习被删除的 tokens;
- 所谓自回归思想,其实就是传统的 CLM 任务学习思路,也就是要求模型按顺序重建连续 tokens。
- GLM 通过优化一个自回归空白填充任务来实现 MLM 与 CLM 思想的结合。
- 迈入 LLM 时代后,针对于超大规模、体量的预训练,CLM 展现出远超 MLM 的优势。通过将模型体量加大、预训练规模扩大,CLM 预训练得到的生成模型在文本理解上也能具有超出 MLM 训练的理解模型的能力,因此,ChatGLM 系列模型也仅在第一代模型使用了 GLM 的预训练思想,从 ChatGLM2 开始,还是回归了传统的 CLM 建模。
4. 大语言模型
- 广义的 LLM 一般覆盖了从十亿参数(如 Qwen-1.5B)到千亿参数(如 Grok-314B)的所有大型语言模型。
- 一般认为,GPT-3(1750亿参数)是 LLM 的开端,基于 GPT-3 通过 预训练(Pretraining)、监督微调(Supervised Fine-Tuning,SFT)、强化学习与人类反馈(Reinforcement Learning with Human Feedback,RLHF)三阶段训练得到的 ChatGPT 更是主导了 LLM 时代的到来
能力:
- 涌现能力(Emergent Abilities):区分 LLM 与传统 PLM 最显著的特征即是 LLM 具备
涌现能力。- 涌现能力是指同样的模型架构与预训练任务下,某些能力在小型模型中不明显,但在大型模型中特别突出。
- 上下文学习(In-context Learning):上下文学习是指允许语言模型在提供自然语言指令或多个任务示例的情况下,通过理解上下文并生成相应输出的方式来执行任务,而无需额外的训练或参数更新。
- 具备上下文学习能力的LLM往往无需进行高成本的额外训练或微调,而可以通过少数示例或是调整自然语言指令,来处理绝大部分任务,从而大大节省了算力和数据成本。
- 在传统 PLM 时代,解决 NLP 下游任务的一般范式是预训练-微调,即选用一个合适的预训练模型,针对自己的下游任务准备有监督数据来进行微调。
- 具备上下文学习能力的 LLM,一般范式开始向 Prompt Engineering 也就是调整 Prompt 来激发 LLM 的能力转变。
- 指令遵循(Instruction Following)
- 指令微调
- 经过指令微调的 LLM 能够理解并遵循未见过的指令
- 逐步推理(Step by Step Reasoning)
- LLM 通过采用思维链(Chain-of-Thought,CoT)推理策略,可以利用包含中间推理步骤的提示机制来解决这些任务,从而得出最终答案。
特点:
- 多语言支持
- 长文本处理
- 拓展多模态
- 挥之不去的幻觉
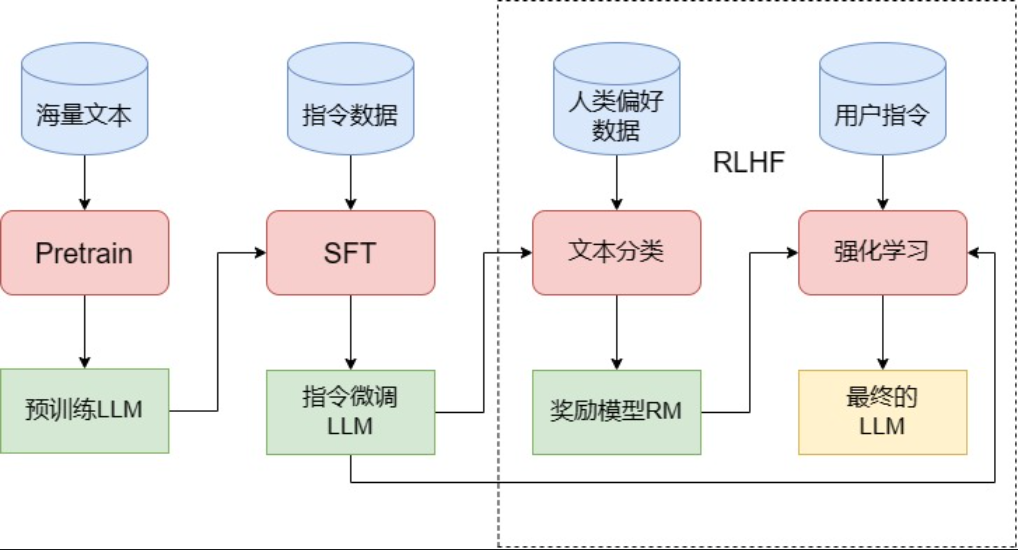
- 一般而言,训练一个完整的 LLM 需要经过图1中的三个阶段——Pretrain、SFT 和 RLHF。
- Pretrain
- 远超传统预训练模型的参数量,同时在更海量的语料上进行预训练。预训练一个 LLM 所需要的算力资源极其庞大。
- 分布式训练框架: 数据并行和模型并行
- 数据并行的情况下,每张 GPU 上的模型参数是保持一致的,训练的总批次大小等于每张卡上的批次大小之和。
- 当 LLM 扩大到上百亿参数,单张 GPU 内存往往就无法存放完整的模型参数。将模型拆分到多个 GPU 上,每个 GPU 上存放不同的层或不同的部分,从而实现模型并行。
- 主流的分布式训练框架包括 Deepspeed、Megatron-LM、ColossalAI 等,其中,Deepspeed 使用面最广。
- 预训练是 LLM 强大能力的根本来源,事实上,LLM 所覆盖的海量知识基本都是源于预训练语料。
- SFT, Supervised Fine-Tuning
- 面对能力强大的 LLM,我们往往不再是在指定下游任务上构造有监督数据进行微调,而是选择训练模型的“通用指令遵循能力”,也就是一般通过指令微调的方式来进行 SFT。
- 所谓指令微调,即我们训练的输入是各种类型的用户指令,而需要模型拟合的输出则是我们希望模型在收到该指令后做出的回复。
- 注意,因为指令微调本质上仍然是对模型进行 CLM 训练,只不过要求模型对指令进行理解和回复而不是简单地预测下一个 token,所以模型预测的结果不仅是 output,而应该是 input + output,只不过 input 部分不参与 loss 的计算,但回复指令本身还是以预测下一个 token 的形式来实现的。
- 多轮对话能力: 模型是否支持多轮对话,与预训练是没有关系的。事实上,模型的多轮对话能力完全来自于 SFT 阶段。
- RLHF, Reinforcement Learning from Human Feedback,即人类反馈强化学习
- 相较于在 GPT-3 就已经初见雏形的 SFT,RLHF 往往被认为是 ChatGPT 相较于 GPT-3 的最核心突破。
- 事实上,从功能上出发,我们可以将 LLM 的训练过程分成预训练与对齐(alignment)两个阶段。
- 预训练的核心作用是赋予模型海量的知识,而所谓对齐,其实就是让模型与人类价值观一致,从而输出人类希望其输出的内容。
- 在这个过程中,SFT 是让 LLM 和人类的指令对齐,从而具有指令遵循能力;
- 而 RLHF 则是从更深层次令 LLM 和人类价值观对齐,令其达到安全、有用、无害的核心标准。
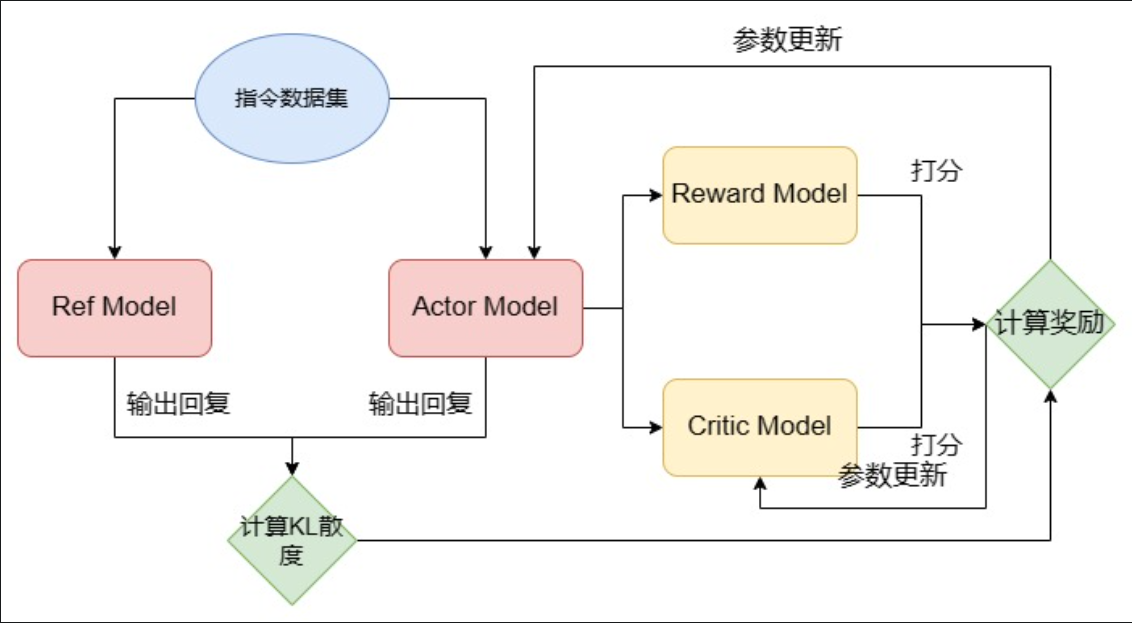
- RLHF 分为两个步骤:训练 RM 和 PPO 训练。
- RM,Reward Model,即奖励模型。RM 是用于拟合人类偏好,来给 LLM 做出反馈的。
- PPO,Proximal Policy Optimization,近端策略优化算法,是一种经典的 RL 算法。
5. 动手搭建大模型
- LLaMA2
6. 大模型训练流程实践
6.1 模型预训练
- Transformers 是由 Hugging Face 开发的 NLP 框架,通过模块化设计实现了对 BERT、GPT、LLaMA、T5、ViT 等上百种主流模型架构的统一支持。
- 在 LLM 时代,模型结构的调整和重新预训练越来越少,开发者更多的业务应用在于使用预训练好的 LLM 进行 Post Train 和 SFT,来支持自己的下游业务应用。
6.2 模型有监督微调
- Chat Template
6.3 高效微调
- Adapt Tuning。
- 即在模型中添加 Adapter 层,在微调时冻结原参数,仅更新 Adapter 层。
- LoRA 事实上就是一种改进的 Adapt Tuning 方法。
- Prefix Tuning。
- 该种方法固定预训练 LM,为 LM 添加可训练,任务特定的前缀,这样就可以为不同任务保存不同的前缀,微调成本也小。
- 目前常用的微量微调方法的 Ptuning,其实就是 Prefix Tuning 的一种改进。
LoRA 微调
- 本征秩(intrinsic rank)
7. 大模型应用
大模型评测、RAG(检索增强生成)以及Agent(智能体)
7.1 LLM 的评测
- open-llm-leaderboard (Open LLM Leaderboard)
- LMArena Leaderboard - a Hugging Face Space by lmarena-ai
- OpenCompass司南
7.2 RAG
- 大模型“幻觉”
- 检索增强生成(Retrieval-Augmented Generation,RAG): RAG 在生成答案之前,首先从外部的大规模文档数据库中检索出相关信息,并将这些信息融入到生成过程之中,从而指导和优化语言模型的输出。
- RAG 的核心原理在于将“检索”与“生成”结合:当用户提出查询时,系统首先通过检索模块找到与问题相关的文本片段,然后将这些片段作为附加信息传递给语言模型,模型据此生成更为精准和可靠的回答。
7.3 Agent
- 大模型Agent是一个以LLM为核心“大脑”,并赋予其自主规划、记忆和使用工具能力的系统。
A Survey of Large Language Models
self-llm
配置conda env
1 | |
Model
1 | |
LLM
https://blog.cosmicdusty.cc/post/Knowledge/LLM/