美国大学生数学建模竞赛学
2022美赛总结
2022年美赛于2月18日早上开始,2月22日上午10:00结束!
备赛 & 比赛
2022年初,同学问我要不要参加美赛,我觉得是花费的假期的时间,不耽误开学后的上课,就一口答应了下来!
期末考试结束的第一天,我就开始询问学长的建议:主要就是跟着清风的是视频学完几个模型,再学习一下论文的排版和写作!
在家学习的效果不能说是特别好,优秀,良好,及格和不及格四个指标来打分的话,我给自己打良好!
在家不仅学习完了清风的大部分视频(因为一开始我就确定不做A,B两题了,后面更新的几章智能算法计划着到最后有时间再学一学),而且也做了笔记。所有的模型也都掌握了个七七八八了!也确实有些部分的知识没有掌握好!
这个假期学习数学建模熬了很多夜,平均在凌晨两点睡觉的,这个时候时间点也基本上都是在学习,手环记录的比这还晚之后入睡的基本都是玩手机玩的!
假期最后,学了美赛论文写作方法和论文的排版,这在美赛写作期间起了很大的作用!
2月15日一天没学习,2月16日就来到青岛了,和队友越好了早来一天时间,在学校附近的一个小旅馆应付了一晚上,讨论一下如何应对美赛!
2月17号进入校园,然后背着书包,拿着电脑去了HZZ(社团)的自习室,之后就傻眼了,钥匙被拿走了,等19号之后才能拿到钥匙。想了个办法去借钥匙,但是最后没能成功!于是就到教学区找了个地方学习!
2月18日,美赛第一天! 选题 & 定题
早上七点起床,到教室,看题!
A题 自行车手的功率分布,PASS!
B题 水和水电共享,PASS
C题 交易策略,关于资产配置的问题,数据分析和预测问题,可能回用到机器学习和回归分析,感觉有点意思,待定!
D题 数据分析?使用我们的分析!看不懂,没有很明确考的是什么!PASS!
E题 用进行碳封存的林业,可持续性发展问题,典型的环境类问题,考虑了一会,觉得有点难,待定!
F题 所有人一个(空间)!小行星采矿如何影响全球公平问题,很新颖,问题在于建立一个合理的模型,自圆其说,且需要大量的数据,待定!
因为16,17号讨论的时候想的是,做E和F两题,这两天,针对这两文看了几篇论文,针对性学习了一下。于是在E和F两题中确定一个!
在第二次看题的时候,想了一下,E题思路不是很清晰,但F题确定了一个基本的方法,AHP——层次分析法!
使用AHP对不同国家进行打分,确定全球的一个公平程度。在引入小行星采矿这个量之后,该参数对之前全球公平模型进行度量,从而确定引入小行星采矿对全球公平的影响!初步思路完成!
第二步,开始找资料,这时候就傻眼了!关于全球公平度量的论文真的是少之又少,关于小行星采矿的论文不少,但是和我们的题目基本上没有什么关系。于是就遇到了美赛的第一个大问题——找不到相关的资料!
之后,队友就在找前几年的论文和网上的资料,看看能不能借鉴到一点东西。而我到谷歌学术我又回过头去看了一下前面的几个题目,重新对其分析,考虑难度和可行性。中午的时候都没有去吃饭,然后队友看到了一篇美赛O奖论文,用的层次分析法,两层指标,度量国家脆弱程度。然后我们将其更改了一下,用来度量全球公平程度!
之后,在建模过程中又遇到了问题,不知道有什么指标,因为实在是没有什么参考论文了!这时候已经是下午了,我们有了换题的打算,准备换C题,且看到网络上很多人选择了C题,C题给了数据,且知道一点思路。于是在C和F之间做权衡。因为C用到了机器学习,甚至会使用深度学习,我们担心编程会出问题,于是仍然选择了F题,毕竟也付出了半天的时间成本。
在确定F题之后,下午到晚上6点多吃饭的期间,就找论文,找参数,最后是确定的四个大的因素。然后就开始了找数据,找的数据大部分都是出于世界银行(World Bank),Our World in Data,联合国(UN)。在找数据期间,也确定下来了影响四个因素的十六个指标。
然后直到晚上十一点左右,都在使用Excel进行数据的整理。数据收集和整理主要是队友B和我。
2月19日,美赛第二天! 数据处理 & 换“战场”
上午和下午的时间基本上还是和昨天定题之后一行,队友B和我进行数据处理整合,最终汇集到了一个总的excel表格!
Excel的很多用法都不会,导致了在数据收集和整理的时候出现了很多问题,造成了时间的浪费!
比赛使用到编程的地方不多,只对收集完成的数据用了一次层次分析法。本来我是负责美赛的编程部分的,但是这次的建模基本上不需要编程,且层次分析法的代码早就已经有现成的了,队友直接把数据丢到程序中跑了一下,的出来了一些结果。
我在此之后绘制了几个流程图表格,并打算做一下数据可视化——使用FineBI进行世界地图的数据可视化。比赛之前只准备了中国和美国的Excel做地图可视化的模板,其他国家的也好做,但是做全球可视化真的没想到怎么做!先是使用Microsoft PoweBI尝试了一下,完全不知道怎么用,又去学习了一下使用FineBI,使用这个比较好上手,也有缺点是要求国家的名称是中文,但是之前在Excel统计的数据都是英文的,于是又使用了DeepL对excel转的PDF进行了翻译,然后又使用做了一个中文的表格,做了半天,最后的结果还是不错的,但是地球上的海洋是中文的,且没找到解决办法,并且打印出来的文件也有问题,一下午的操作没有什么成果!
队友A和B下午的时间在对模型进行完善,自圆其说,讨论了很多的方案,有的被否定了,也有的被加入到了模型中!
第一个模型就是用四个因素和16个指标度量全球公平。处理数据,得出全球各个国家的公平数值,然后用方差度量全球的公平程度,一些细节因素在想的过程中还是很难想的。
晚上拿到了社团自习室的钥匙,于是就把阵地转移到了社团自习室,24小时通宵供电,无人监管,尽情的熬夜!
晚上的时间我仍然是在作图,主要使用Draw.io这款软件绘制流程图。
我在绘图的同时,与队友讨论并完善第一个模型,第一个模型还有很多说不通的地方。
2月20日,美赛第三天! 数据可视化 & 第一个模型的写作
队友上午时间把第一个模型做的比较完善了,确定了参数之间的相互影响关系。由于之前数据可视化做的不好,实在是没什么办法了,我就采取了一个很笨拙的办法,在pixel map这个网页上下载了SVG格式的全球地图。然后把每个国家独立出来,一个个国家对照着excel表格进行填色。忙了将近三个小时,完成了数据量的一半左右,期间还与队友产生了分歧,关于数据可视化,队友A认为另一种指标来度量更好,而我觉得两种差不多,并且我已经做了很多了,推倒重来太可惜了,就产生了矛盾的和分歧,因为我在作图,我还是一意孤行坚持做完!我做到一半多的时候,因为实在是太繁琐,太麻烦,太浪费时间了,我就突然想到了Python!Python能做很多的高效工具啊!我之前怎么把这事儿给忘了!!!我平时使用Python其实挺多了,不知道为什么在关键时刻把它忘记了!
花了几分钟学习了一下Python的几个函数,看了几个例题,十来分钟就写出来了一个十几行的程序,然后运行程序,可视化地图一下子就做出来了!啊!!!我上午的时间又都被浪费了!有了这个Python程序之后,又把队友的指标参数做了可视化,最终确定队友的图像作为论文中的图像。
中午没吃饭,下午两点多一起出超市买的面包,顺便也买了晚上的面包!吃完饭之后,都趴桌子上睡了一小会儿!
下午队友B开始把写作模型一的中文论文。这期间我没什么事情,我就在看网上学习了一下Python的Networkx库(寒假美赛期间就规划了学习这两个库,但是因为后期时间有点紧张,没有学),因为美赛更喜欢使用Matlab和Python做的图,但是我都是用Draw.io绘制的图形,就想学一学,看看能不能做出几个亮眼的图片。最后因为时间原因放弃了,只做了一个网络图,但最后并没有放到论文中。
晚上的时间就是把队友写好的文字进行翻译,之后再进行论文的排版,因为我看了清风的论文写作和排版的视频,我和队友B把第一本部分进行排版,队友A继续找参考资料,参考论文,进行第二个模型的建立。
2月21日,美赛第四天! 上课&美赛
今天开学了,上午的三四节和下午一下午我都有课,这期间我去上课了,队友没有这么多的课,这期间他们完成了第二个模型的初步建立。
下课之后,我回到了自习室,因为建立了新的模型,又需要我绘制结构图等,于是我再次绘制了几张图。同时需要一些数学函数图形,我就使用Geogebra软件,绘制了几个函数图形。
晚上的时间,共同商讨着完成了最后的模型。一起进行了模型二的修改,模型三是使用的优秀论文中的计算方法,比较快的就完成了。
图片什么得也基本都绘制完成了,最后就是写作部分了!
由于之前写作了不少,我们计划到22号凌晨两点之前完成所有的工作!但是计划不如变化。写作的论文中出现了一些尚未改正的参数,排版需要更改,公式需要编号等。这个部分由我和队友B完成了。完成了所有的工作之后,最后只剩下了Summary要写,这时候已经是凌晨两点了!
2月22日,美赛第五天!最后的冲刺!
凌晨两点之后,我们三个都有点坚持不住了,就决定先休息一下,找了椅子拼凑了一下,凑合着睡了一个小时,有点冷!
三点起来,开始完成Summary,两个小时,三人商讨着完成了Summary,并检查了一下排版,确定了没什么问题之后,打印输出成PDF,在05:05发送了邮件,交上去了!
之后收拾完了,各自回去睡觉,第二天还有课要上!
结束
我觉得这是一次不算特别成功的建模,但毕竟我们三人都只学习了一个月的时间,能做出这样子还算基本满意!
- 本来计划是我负责编程部分,涉及到的数学太少了,没有多少程序可以写,然后在建模过程中迅速换了战略,主要进行收集数据,使用Python优势处理数据,使用Python和绘图软件绘制解释性的图片,也花了不少精力在论文排版。建模部分参与不算不多,第一个模型的建立还参与了一些,第二、三个模型建立的时候,一是在忙着绘图,二是需要上课,建模初期参与少,主要是提出想法完善模型。
- 因为是开放的题目,没有什么标准答案。第一个模型度量全球公平,我觉得比较新颖;第二个模型,引入了小行星采矿这个变量之后,对全球公平的影响,我觉得我们想的可能有点简单了,我觉得这里应该建立一个很大的模型,关于分配的模型,但是不知道用什么参数来衡量,我们最后的模型只做了很少一点这部分的内容。(当然也有可能是想法是错的)
- 学习时间太短了,只有差不多一个月的时间。因为前期不了解数学建模,以为Matlab会占据很大的部分,我就在年前系统性地学习了Matlab的语法。但是在实际使用中,用不到这么多复杂的东西,因此也浪费了很多的时间。年前学习清风的建模视频的时间比较少,导致了后面出现了学习时间紧张的问题。
- 论文写作也有点问题,大部分的内容都是直接翻译,复制粘贴的,只在最后检查了一下基本的语法,对其进行了少量的润色。特别是Summay部分,我觉得用的时间太少了,时间其实也算够了,主要还是大家有点熬不下去了,想快点解决,早交上去早结束。
- 前期学习的时候,没有进行实践,也没有读很多的论文,这也是一个很大的问题。没有什么经验,全凭着自我感觉,没有参数经验,问题还是挺大的!
结果
2022.5.6的上午正在上课,群里发来了一张截图!我们得到M奖!相当不错!在结果出来之前根本没想到能拿到这么好的奖项!班级里的其他队伍拿的是H或者是S奖,总体来说我们队伍是做的最好的!
仅此!
附:我们的荣誉!

美赛:建模+编程+写作
层次分析法
层次分析法 AHP讲解
- 层次分析法主要解决评价类问题——评价类问题用打分解决
权重——权重和为1
表格:指标和指标权重,方案n
关键词:评价指标,评价体系
问题:1. 评价的目标 2. 可选方案 3. 评价指标
问题解决
背景材料搜集:知网,百度学术,谷歌学术,万方,虫部落-快搜(清风推荐);头脑风暴;
分而治之思想:两个两个比较,排列组合问题
矩阵
正互反矩阵(判断矩阵)
一致矩阵:各行(各列)之间成倍数关系的正互反矩阵

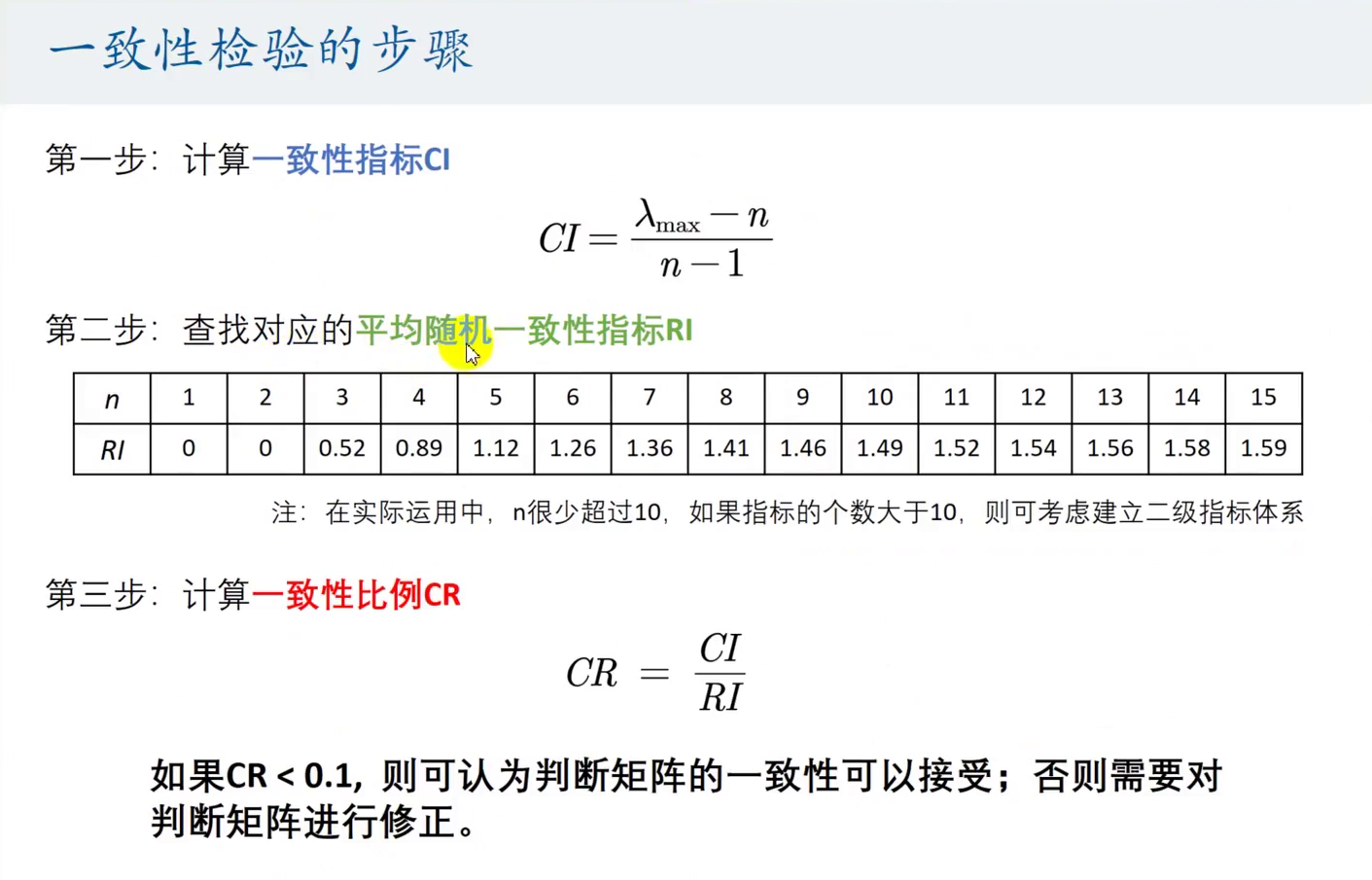
一致性检验一致性检验的步骤(计算公式)
1 | |
权重
1 | |
- 层次分析法基本思路和实现

- 分析系统中各因素之间的关系,建立系统的递阶层次结构,目标层,准则层,方案层;
清风推荐作图软件,亿图,Visio,processon - 构造判断矩阵;
判断矩阵的数据可以自己选择,但所要结合实际,有一定的准确性;
构造判断矩阵的时候尽量不要构造一致矩阵,构造一个判断矩阵,进行一致性检验,若通不过,继续修改判断矩阵,直到能够通过一致性检验 - 由判断矩阵计算被比较元素对于该准则的相对权重,并进行一致性检验
三种计算权重的方法:三种方法都要使用
一致性检验:三步走
一致性检验不通过,需要修改判断矩阵 - 计算各层元素对系统目标和合成权重,并进行排序
使用excel计算
- 层次分析法的局限性
- 决策层不能太多
- 决策层中指标的数值已知,层次分析法不具有客观性!
模型拓展部分
- 准则层可以有多个;
- 准则层的每个元素不一定是对应着方案层的所有元素,可能只是一般部分的元素;
- 准则层中的一个元素之对应着他自己的几个方案,反过来讲就是每个方案都只受一个决策层元素影1.响
代码讲解部分
- matlab基本使用
分号
注释
多行注释:Ctrl+R
多行取消住宿:Ctrl+Tclear:清除工作区的变量
clc:清空命令行
clear;clc——“初始化”disp()输出函数
向量或矩阵同一行元素用“,”或“ ”隔开
向量或矩阵的不同行元素用“;”隔开字符串合并
strcat(s1,s2,s3);
[‘hello’,’world’,’!’]
[‘hello’ ‘world’ ‘!’]num2str():数字转换成字符串
input()输入函数
A=input(‘请输入A的值’):A可以是数,向量,矩阵,字符串sum()函数
- 向量(行向量或在列向量):直接求和
- 矩阵:根据行和列的方向作区分
- sum(A):按照列求和,得出每一列的和,结果为行向量;
- sum(A,1):与sum(A)等价;
- sum(A,2):按照行求和,得出每一行的和,结果为列向量;维度dim,dim=1(默认),表示按照列;dim=2,表示按照行;
- sum(A(:))=sum(sum(A)):对整个矩阵进行求和;
- A::将矩阵变成列向量;
- 矩阵元素的提取
- 指定某一行某一列的一个元素:A(1,2)
- 指定某一行的全部元素:A(1,:),“:”表示取所有元素
- 指定某一列的全部元素:A(:,1)
- A([2,5],:) % 只取第二行和第五行(一共2行)
A(2:5,:) % 取第二行到第五行(一共4行)
A(2:2:5,:) % 取第二行和第四行 (从2开始,每次递增2个单位,到5结束)
1:3:10
A(2:end,:) % 取第二行到最后一行
A(2:end-1,:) % 取第二行到倒数第二行 - 全部元素(按列拼接的,最终输出的是一个列向量):A(:)
- size(),返回值为行向量,[矩阵的行数,矩阵的列数]
- size(A,1),返回行数
- size(A,2),返回列数
- [r,c] = size(A)
repmat()
B = repmat(A,m,n):将矩阵A复制m×n块,即把A作为B的元素,B由m×n个A平铺而成。矩阵运算
“”号和“/”号代表矩阵之间的乘法与除法(A/B = Ainv(B))
两个形状相同的矩阵对应元素之间的乘除法需要使用
“.*”和“./”乘方:A.^2;
A.*A
eig(A),特征值和特征向量
[V,D]=eig(A)
求矩阵A的全部特征值,构成对角阵D,并求A的特征向量构成V的列向量。(V的每一列都是D中与之相同列的特征值的特征向量)find()
https://www.cnblogs.com/anzhiwu815/p/5907033.html
ind = find(A):返回向量或者矩阵中不为零的元素的位置索引判断符号
if() 判断语句
- 用程序实现层次分析法
- 矩阵的输入;
- 用三种方法求得权重;
- 对判断矩阵进行一致性检验;
- 在excel中,根据程序算出的权重列表,计算得出最优解。
不理解之处

TOPSIS
TOPSIS 模型讲解
逼近理想解排序法,优劣解距离法
构造计算评分(公式)


- 比较对象要大于两个;
- 比较的指标是多方面的;
- 指标有没有最大值和最小值。
极大型指标(效益型指标)
极小型指标(成本型指标)
统一指标类型:
将所有的指标转换成极大型称为指标正向化
标准化处理,消除量纲的影响
TOPSIS步骤
- 将原始矩阵正向化;
四种指标:极大型指标,极小型指标,中间型指标,区间型指标;
极小型->极大型指标
1 | |
中间型->极大型指标

区间型->极大型指标

正向化矩阵标准化

计算得分并归一化

模型拓展
评价指标的权重:带权重的TOPSIS
用层次分析法给这m个评价指标确定权重
层次分析法具有主观性,为了修正TOPSIS,我们使用熵权法;
代码部分
- load
加载mat数据文件 - 判断是否需要正向化处理
需要正向化则直接调用正向化的函数(自己声明的函数)
函数的输出值就是已经正向化的矩阵
自定义函数,需要放到一个m文件中1
2function [输出变量] = 函数名称(输入变量)
end - 对正向化的矩阵进行标准化
- 计算与最大值的距离和最小值的距离,并算出得分
sort()函数
向量:sort(A):按照升序排列,sort(A,’descend’):按照降序排列
矩阵:sort(A)与sort(A,1)等价:按照列排序,sort(A,2):按照行排序;
magic():幻方矩阵,矩阵的每一列和相等;
数据可视化:excel作图:清风推荐条形图
基于熵权法对TOPSIS模型的修正
熵权法是一种客观赋权的方法
依据的原理:指标的变异程度(方差)越小,所反映的信息也就越少,其对应的权重也应该越低;
信息量的度量——概率
自信息
信息熵
熵权法计算步骤
- 判断输入的矩阵中是否存在负数,如果有则要重新标准化到非负区间
矩阵正向化处理
矩阵标准化 - 计算第j项指标下的第i个样本所占的比重,并将其看作相对熵计算中用到的概率
- 计算每个指标的信息熵,
并计算信息效用值,
并归一化得到每个指标的熵权
熵权法的代码
灰色关联分析(美赛不用)
模型基本介绍
系统分析和综合评价
系统分析,分析自变量对结果影响大小
数理统计:回归分析,方差分析,主成分分析
灰色关联分析,对数据量的大小和样本的规律性没有要求
灰色关联分析的思想是根据序列曲线几何形状的相似程度来判断其联系是否紧密。曲线越接,相应序列之间的关联度就越大,反之就越小;
应用一:进行系统分析
画统计图(用Excel),并根据图表做几条简单的分析
确定分析数列
1
2母序列(参考数列,母指标):反映系统行为的数据序列->类似于因变量Y(只有一个);
子序列(比较数列,子指标):影响系统行为的因素所组成的数据序列->类似于自变量X(可以有多个);对变量进行预处理(目的:去量纲,缩小变量范围简化计算)
对母序列和子序列中的每个指标进行预处理:先求出每个指标的均值,在用该指标中的每个元素都除以其均值;计算子序列中各个指标与母系列的关联系数(小数点后四位数字)
两极最小差,两极最大差
计算关联系数
灰色关联度

通过比较三那个子序列和母序列的关联度可以得到结论:
找到灰色关联度最大的那个指标,该子指标对母指标的影响最大;
讨论:
美赛不要用灰色关联分析,美赛用传统的数理分析方法(回归分析,方差分析,主成分分析)

应用二:用于综合评价
(类似于TOPSIS联合熵权法)

模糊综合评价
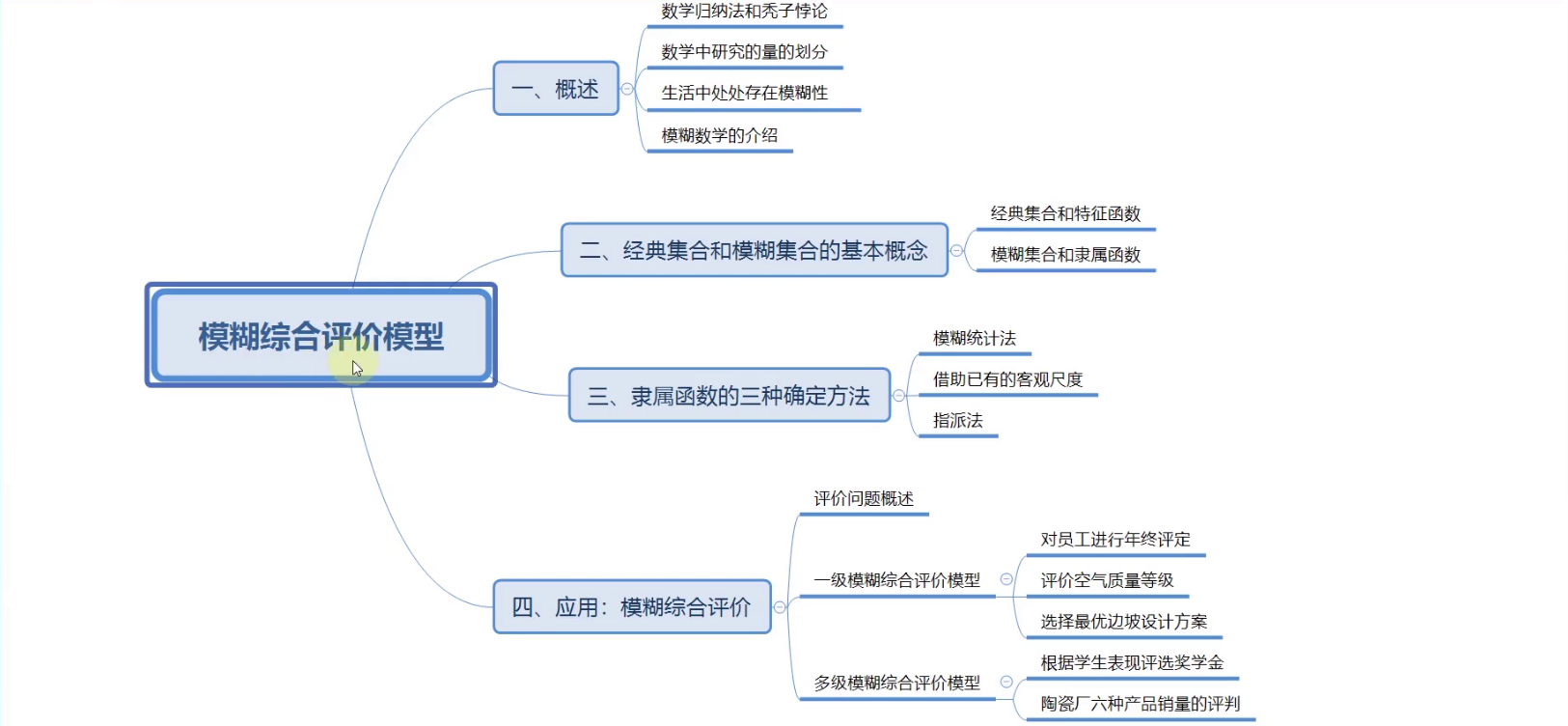
模糊综合评价概述
数学归纳法和秃子悖论
量变引起质变数学上就算模糊的概念数学中研究的量的划分
1 | |
生活存在的模糊性
确定性:性别,年龄,身高……
模糊性:高,帅,白,年轻……模糊数学

经典集合和模糊集合的基本概念
- 经典集合与特征函数
- 论域:我们感兴趣的一些对象集合
- 模糊集合和隶属函数
- 隶属函数(分段函数),隶属函数不唯一
- 隶属度
- 模糊集合的三种表示方法
1 | |

- 模糊集合的分类
偏小型——隶属函数递减
中间型——隶属函数先增大后减小
偏大型——隶属函数递增
隶属函数的三种确定方法
模糊统计法(比赛中用的少,因为需要发问卷,实际研究中应用更多)
原理:找到多个人对同一个模糊概念进行描述,用隶属频率去定义隶属度借助已有的客观尺度(需要有合适的指标,并能收集到数据)
- 论域
- 模糊集
- 隶属度(指标介于0-1至今(归一化处理))
- 指派法(根据问题的性质直接套用某些分布作为隶属函数,主观性强)
博客网站链接:(1条消息) 模糊数学模型(一): 隶属函数、模糊集合的表示方法、模糊关系、模糊矩阵_冷月无声的博客-CSDN博客_常用的模糊函数分布表


- 概述
1 | |
一级模糊综合评价模型
在指标个数较少的考核中,运用一级模糊综合评判,而在问题较为复杂,指标较多时,运用多层次模糊综合评价
步骤:确定因素集。评价角度
确定评语集。评价值 评价等级
确定各因素的权重。使用Delphi法(专家调查法):征求专意见后,再反馈给专家,再次征求意见,直到意见的统一;其他方法:无数据:层次分析法;有数据:熵权法。
确定模糊综合判断矩阵(关键)。

综合评判。模糊变换。
多级模糊综合评价模型
因素中元素较多,我们可以对其进行归类归类后,可以简化我们的计算。
确定权重的时候,指标越少,越容易判断权重
Excel绘制统计图
美赛:英文写作和作图比建模更重要
一般不直接在图中加标题,把图的标题放在论文中
饼图
- 边框无线条
- 类别太多:不用饼图而是柱状图
- 类别太少:不画饼图
- 划分的类别不是全集:加一个“其他”类别
- 先排序后画饼图
- 复合饼图

柱状图和条形图
- 只有一列数据:柱状图
- 有两列数据:柱状图
- 三类柱状图:普通柱状图,堆积柱状图,百分比柱状图
- 换一个角度画图——切换行和列,先排序后作图
- 条形图(横折的柱状图):类别特别多的时候,如果要加入数据标签,则应该使用条形图
- 双向条形图
- 用柱状图可视化回归结果
直方图
频数分布直方图
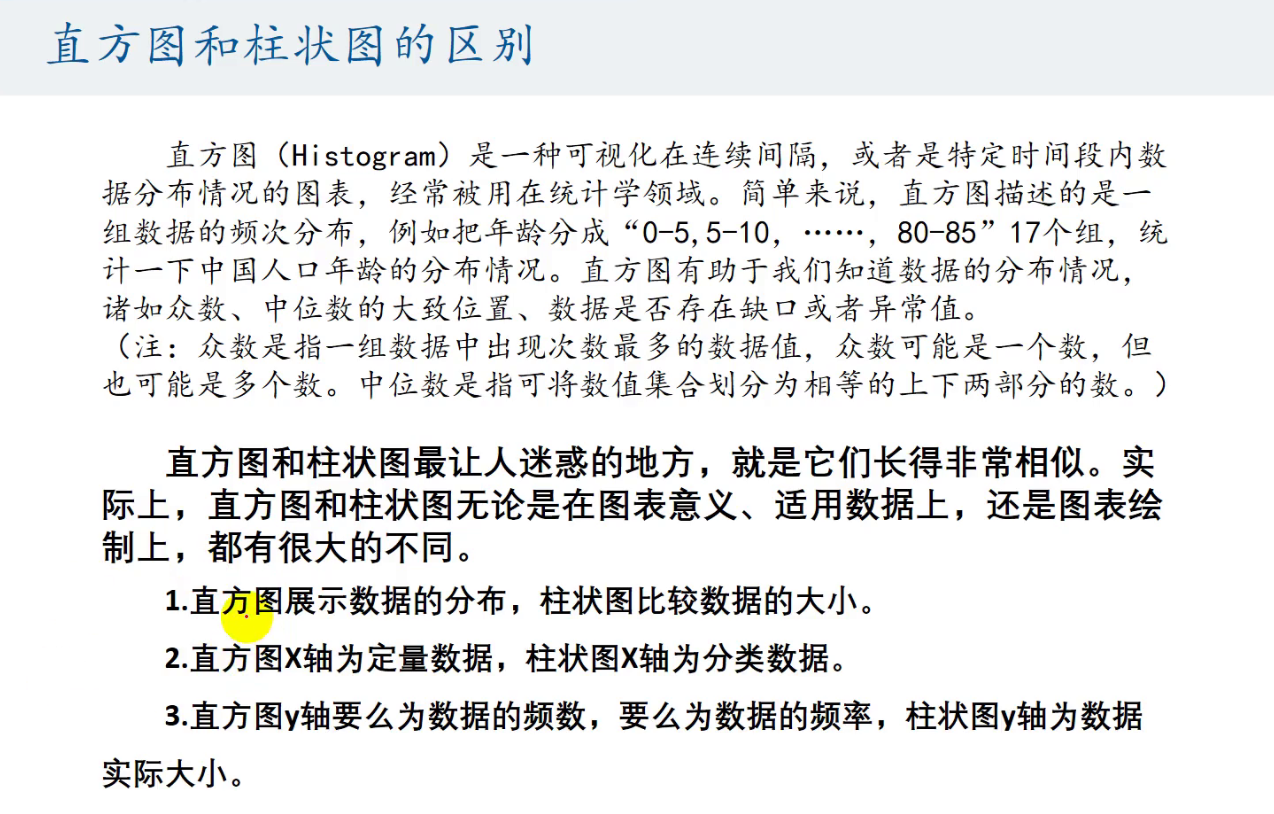
组距对直方图的影响
频率分布直方图:先用excel计算出频率
折线图
- 超长时间序列图
- 双坐标轴在折线图
- 柱型图顶端的折线图
散点图
- 普通散点图
- 带标示的散点图
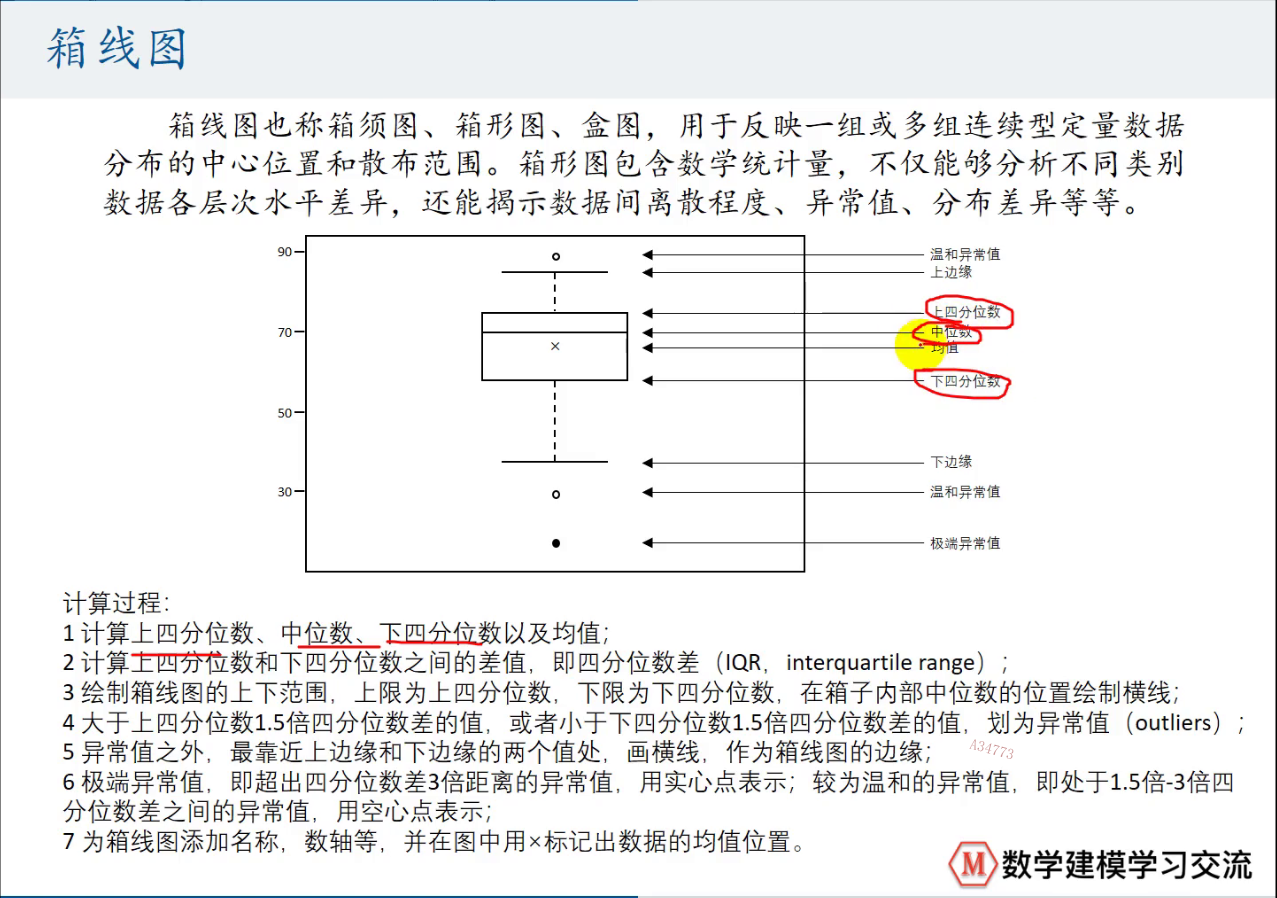
箱线图

插值算法
数据很少的时候,不足以支撑分析的进行,这时候就需要使用数学的方法,模拟产生一些新的但又比较靠谱的值来满足需求。
一维插值问题
多相式插值:
拉格朗日插值法
龙格现象:高次插值会产生龙格现象,即在两端处波动极大,产生明显的震荡。分段插值:
分段线性插值法
分段二次插值法(分段抛物插值)牛顿插值法
差商
也存在龙格现象埃尔米特插值原理
分段三次埃尔米特插值
matab函数:p=pchip(x,y,new_x)1
2
3x:已知的样本点的横坐标;
y:已知的样本点的纵坐标;
new_x:要插入处对应的横坐标;plot()函数

三次样条插值
spline(x,y.new_x)
n维数据的插值

插值算法可以用于预测
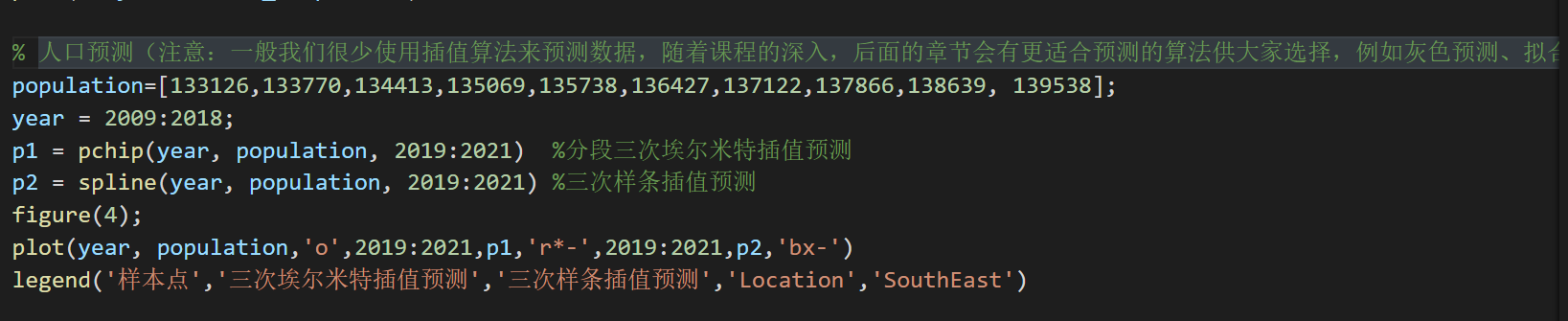
建模实例
两组数据,第一组数据的时间是:第一周,第二周,第三周……
第二组的数据的时间是:第一周,第三周,第五周……
因此,需要先把第二组的数据使用插值算法扩展到第一周,第二周,第三周……
subplot()函数
拟合算法
拟合算法与插值算法的区别:与插值问题不同,在拟合问题中不需要曲线一定经过给定的点。拟合问题的目标是寻找一个函数(曲线),使得该曲线在某种准则下与所有的数据点最为接近,即曲线拟合的最好(最小化损失函数)。
插值算法:找到的函数经过所有的样本点
拟合算法:误差尽量小
拟合算法讲解
- 确定拟合曲线
最小二乘法
使用matlab求解最小二乘法
1 | |
- 评判拟合的好坏
拟合优度(可决系数)
量纲会影响SSE
1 | |
线性函数
在函数中,参数仅以一次方出现,且不能乘以或除以其他任何参数,并且不能出现参数的复合函数形式
matlab计算拟合优度
曲线拟合工具箱
Curve Fitting Tool
相关性分析
相关系数
皮尔逊相关系数
斯皮尔曼等级相关系数
相关系数可以用来衡量两个变量之间的相关性的大小,根据数据满足的不同条件,我们要选择不同的相关系数进行计算和分析。
总体:所要考察对象的全部的个体叫做总体
样本:从总体中所抽取的一部分个体叫做总体的一个样本。
使用样本均值,样本标准差来估计总体的均值和总体的标准差
- 总体皮尔逊相关系数
总体均值与协方差
皮尔逊相关系数可以看成是剔除了两个变量量纲影响,即将x和y标准化后的协方差

样本皮尔逊相关系数

皮尔逊相关系数的理解误区
相关系数只是用来衡量两个便利线性相程度的指标;
也就是说,你必须确定这两个变量是线性相关的,然后这个相关系数才能告诉你他两个相关程度如何需要注意的点
- 非线性相关也会导致线性相关系数很大
- 离群点对相关系数的影响很大
- 如果两个变量的相关系数很大,也不能说明二者相关,可能是受到异常值的影响
- 相关系数计算结果为0,只能说不是线性相关,不能说不相关
- 总结
- 如果两个变量本身就是线性的关系,那么皮尔逊相关系数绝对值大的就是相关性强,小的就是相关性弱
- 在不确定两个变量是什么关系的情况下,即使算出皮尔逊相关系数,发现很大,也不能说明两个变量线性相关,甚至不能说明他们相关,我们一定要画出散点图来看才行
相关性大小

例题
- 计算基本统计量,进行描述性统计

- 法一:使用matlab
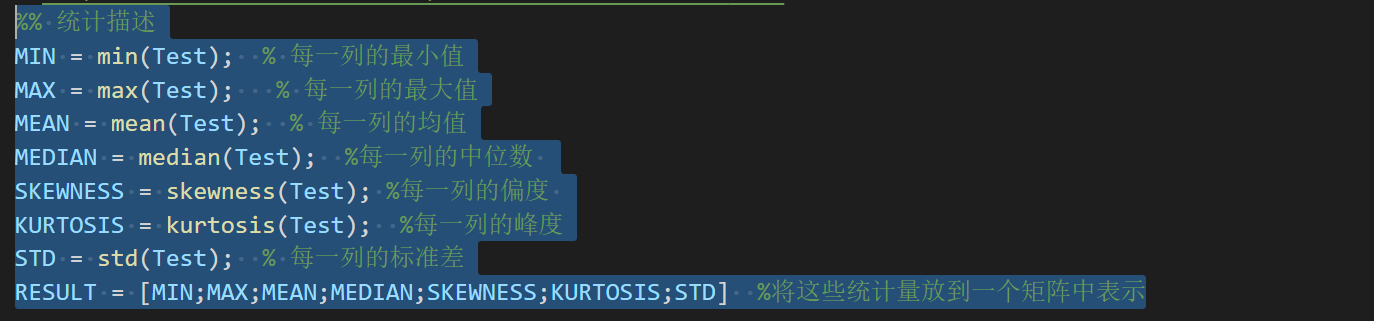
法二:使用excel
法三:使用spss
分析-描述统计-描述
画出散点图
使用excel或SPSS,推荐使用SPSS(图形 - 旧对话框 - 散点图/点图 - 矩阵散点图)
计算皮尔逊相关系数
matlab:corrcoef()函数
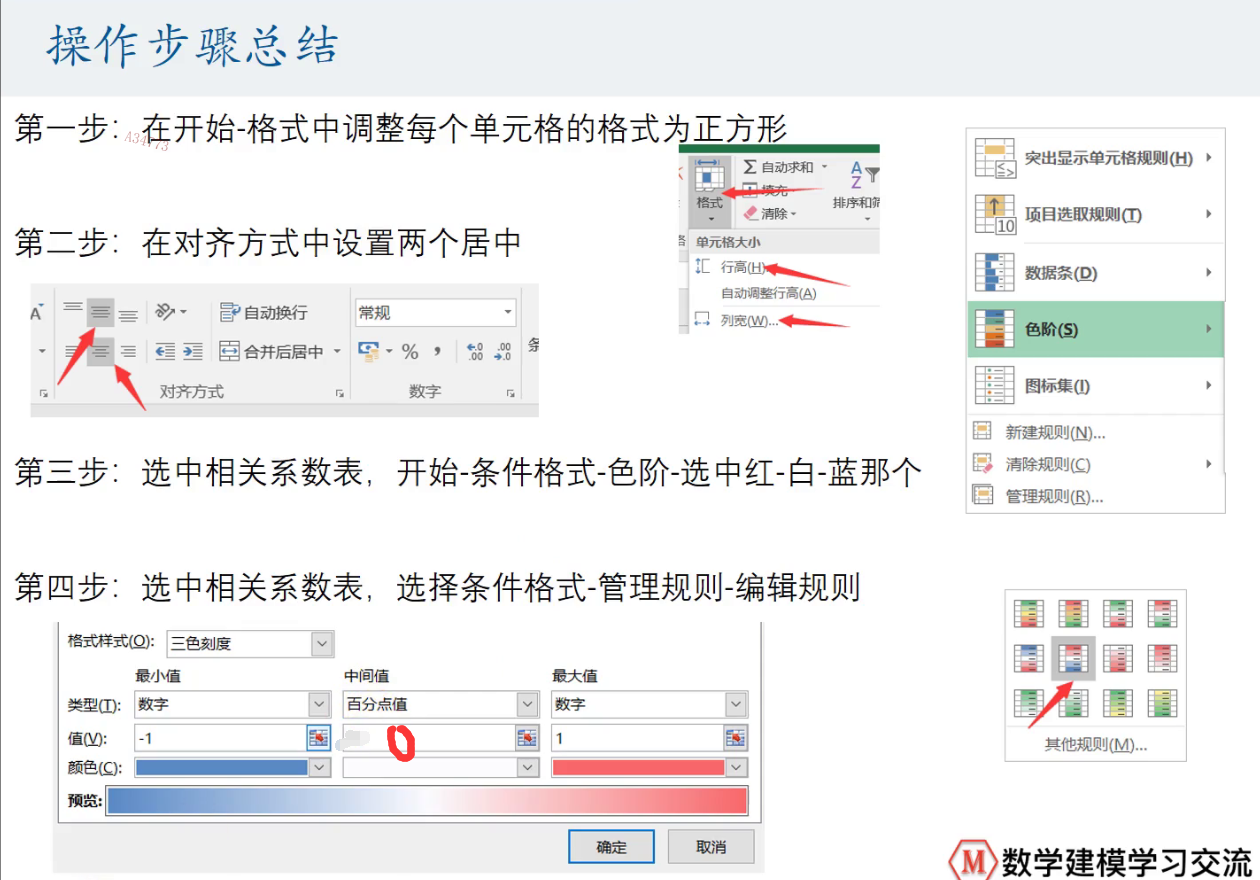
在excel中对相关系数表格进行美化
- 设置好基本格式
- 开始-条件格式-色阶
- 开始-条件格式-色阶-管理规则,梗概最小值,中间值,最大值
假设检验
原假设
置信水平:相信原假设成立的概论Beta
临界值
显著性水平:我们有多大的可能拒绝原假设(Alpha=1-Beta)(犯第一类错误的概率:原假设是正确的我们却认为它错了)
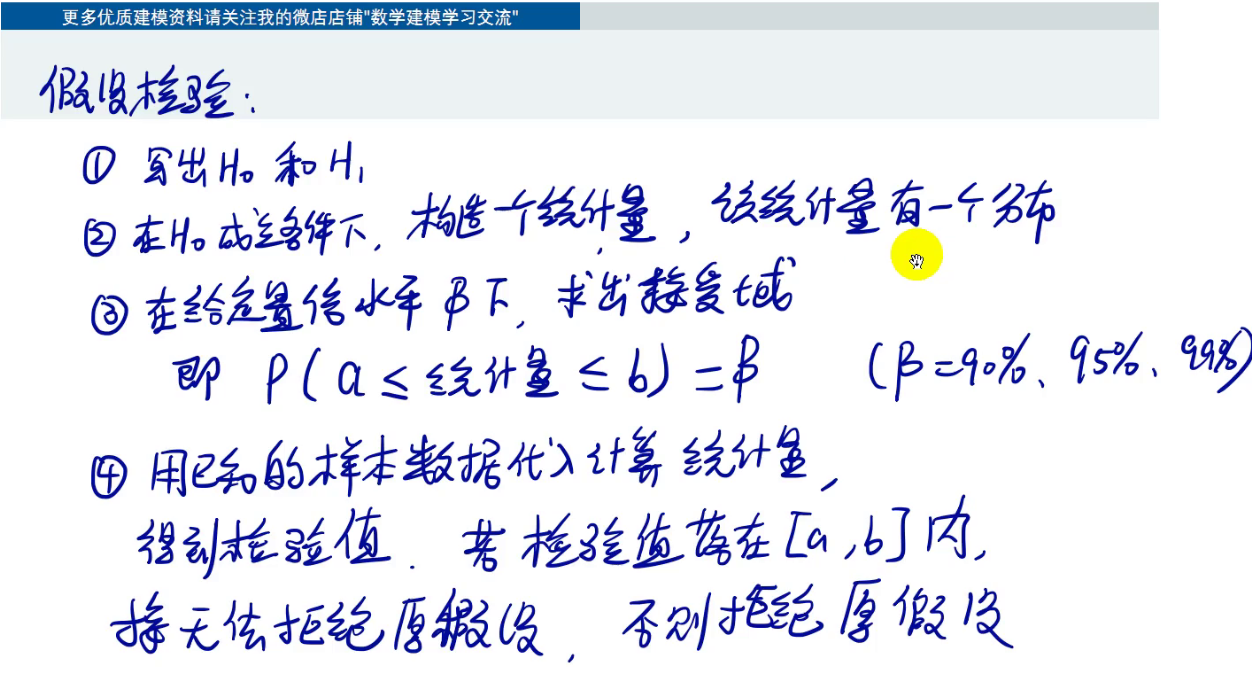
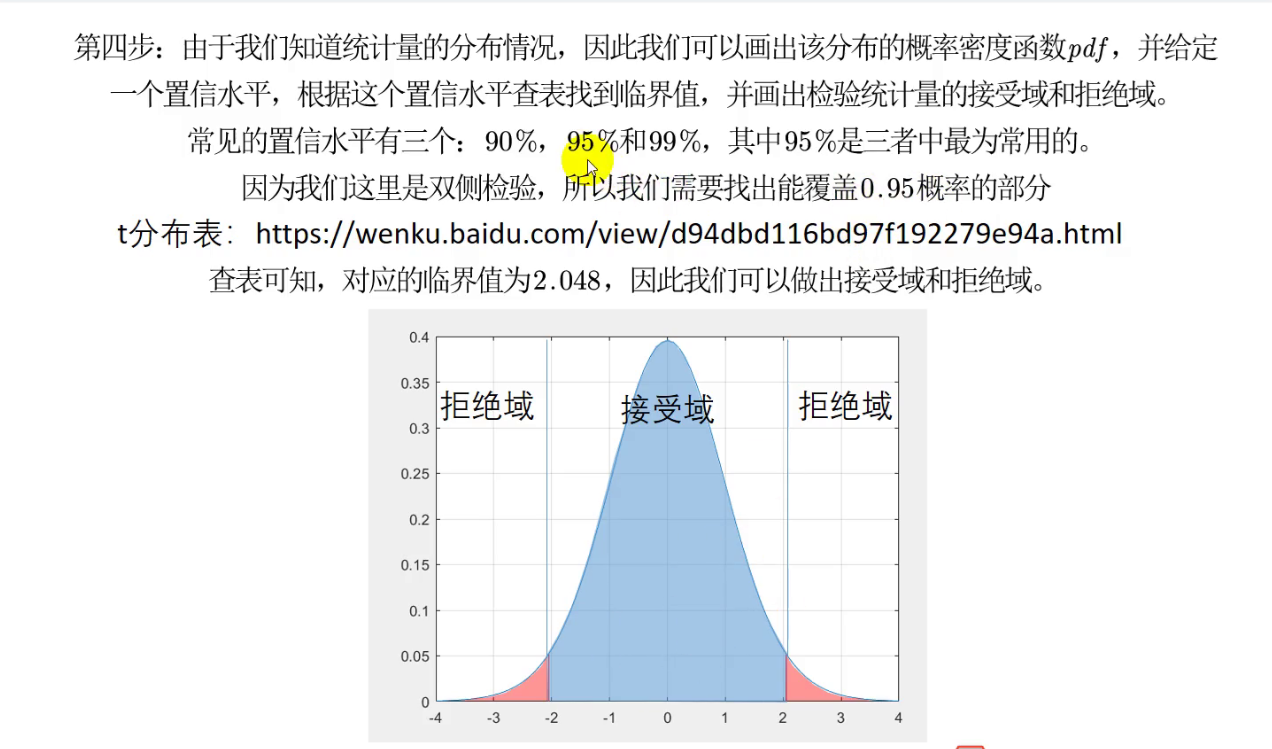
假设检验的步骤
- 确定原假设(H_0)和备择假设
- 在原假设成立的条件下,根据要检验的量构造一个分布
标准正态分布,t分布,F分布,卡方分布 - 画出这个分布的概率密度图
- 给一个置信水平Beta(相信H_0成立的概率)
概率密度函数pdf-f(x)
离散型随机变量
连续型随机变量
累计密度函数cdf-F(x)

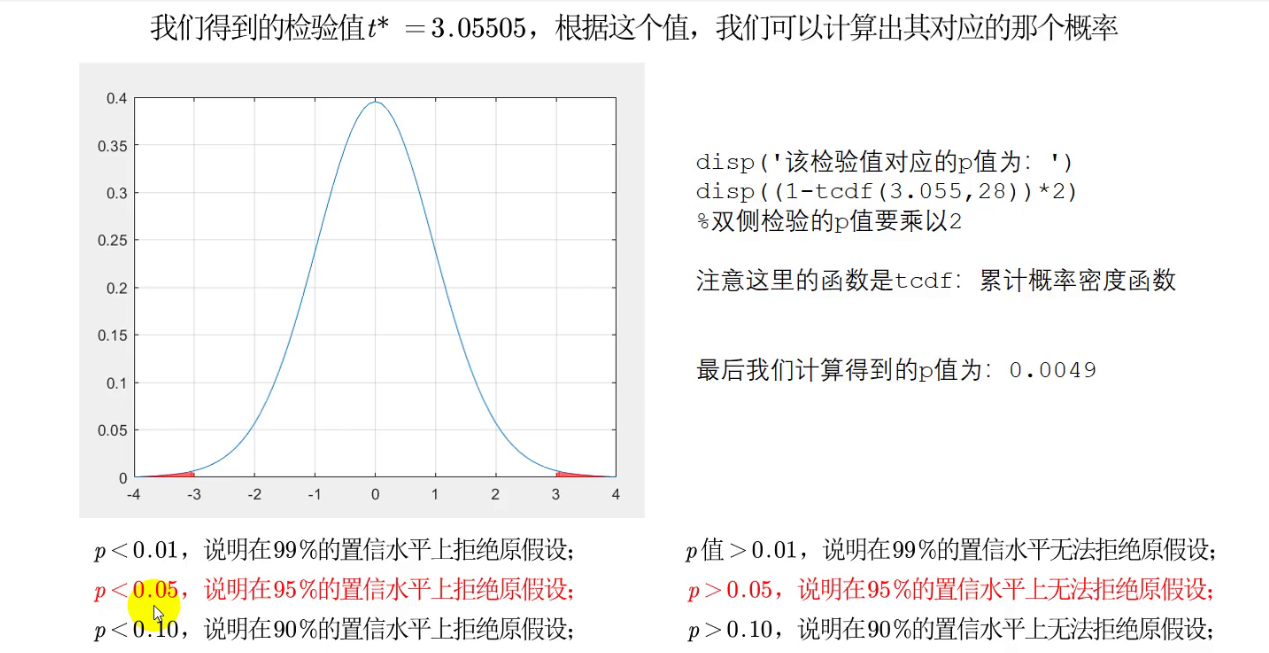
皮尔逊相关系数假设检验


p值判断法
皮尔逊相关系数假设检验的条件
- 实验数据通常假设是成对的来自于正态分布的总体。
- 实验数据之间的差距不能太大。(皮尔逊相关性系数受异常值的影响比较大)
- 每组样本之间是独立抽样的。
对数据进行正态分布检验
- 正态分布JB检验(大样本,n>30)
偏度和峰度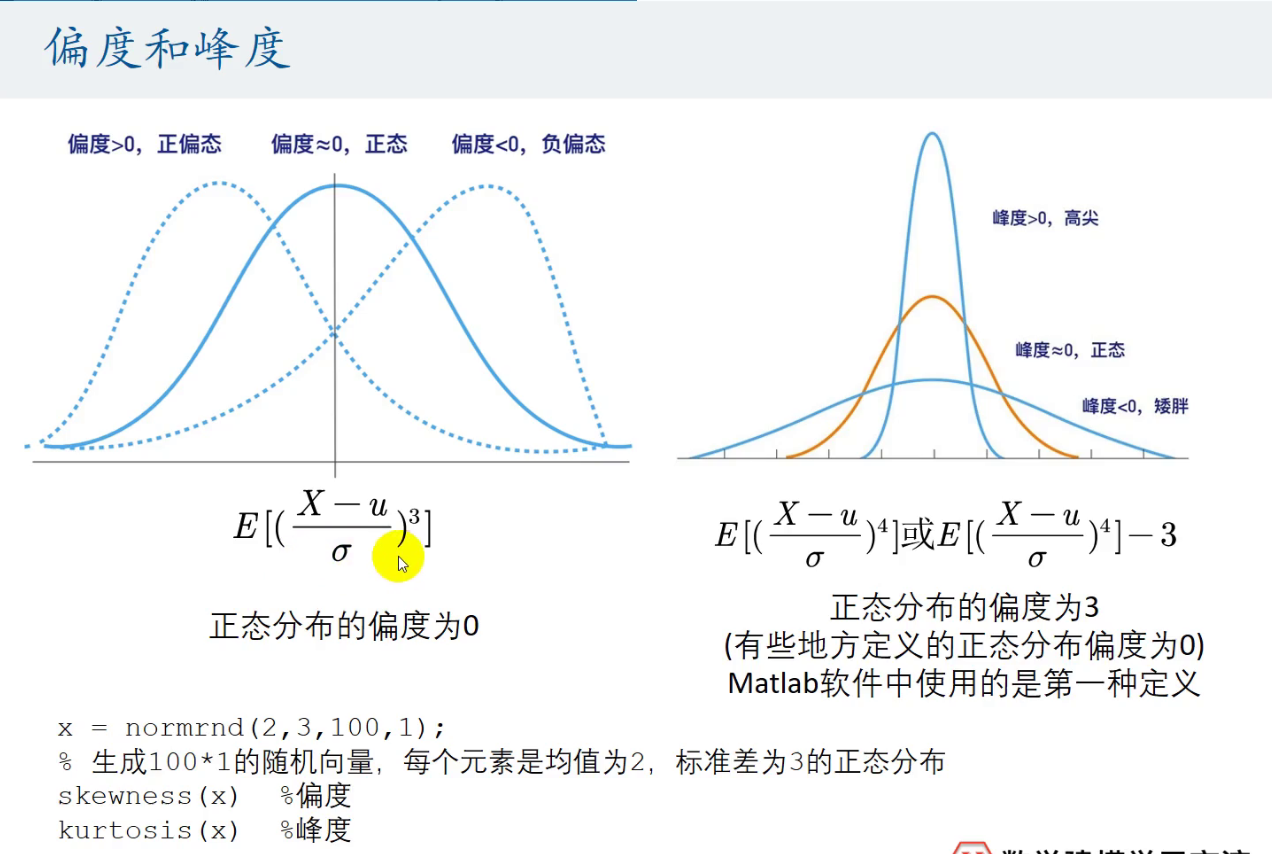

matlab:jbtest(x,alpha)
x:不能是矩阵,只能是列向量

- Shapiro-wilk检验(小样本,3<=n<=50)
夏皮洛-威尔克检验
matlab没有提供相应函数,只能使用SPSS
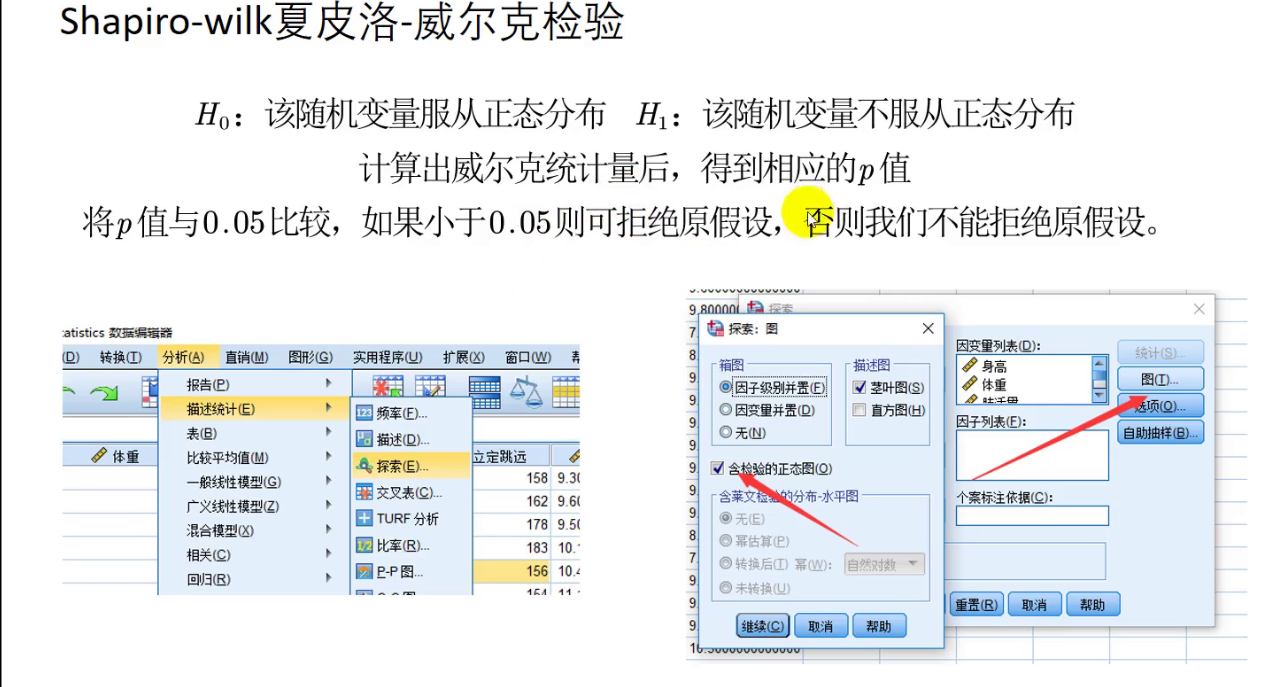
matlab没有提供相应函数,只能使用SPSS
- Q-Q图(数要求据量超级大)——不推荐使用

matlab:qqplot(x)
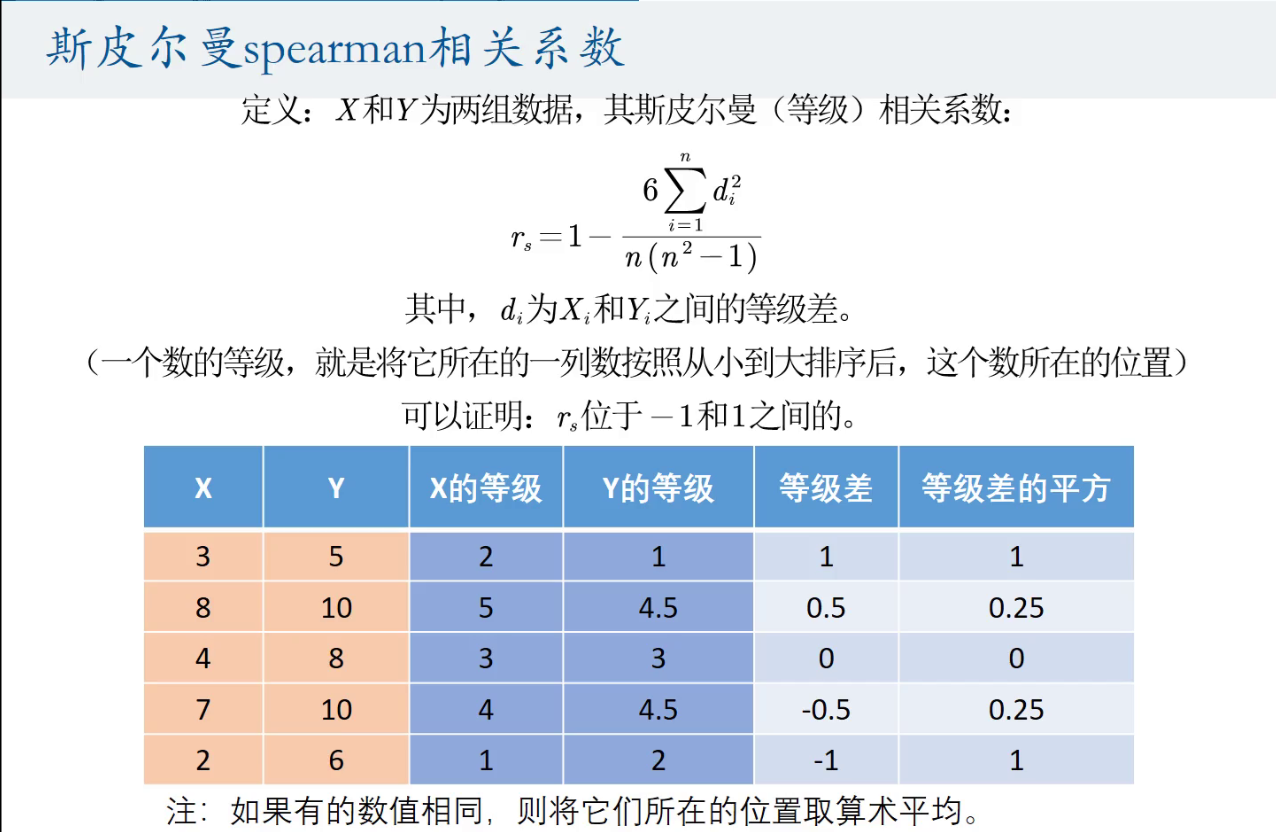
斯皮尔曼相关系数
两组数的等级差
一个数的等级
斯皮尔曼相关系数使用matlab计算

小样本:
斯皮尔曼等级的相关系数的临界值
样本相关系数r必须大于等于表格中的临界值,才能得出显著的结论
大样本:
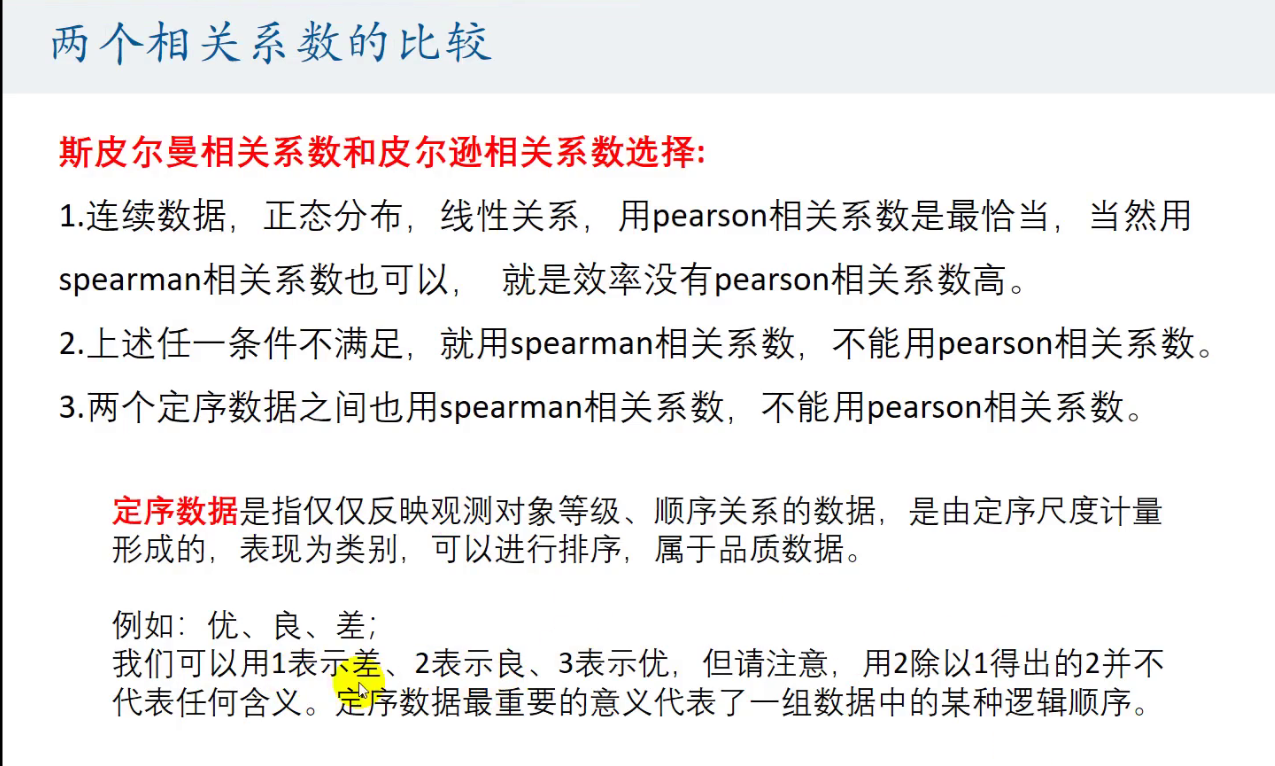
两种相关系数的比较
正态分布均值的假设检验
图论
图的概念
图(Graph)
图的顶点集V
图的边集E
图的绘制
法一:https://csacademy.com/app/graph_editor/
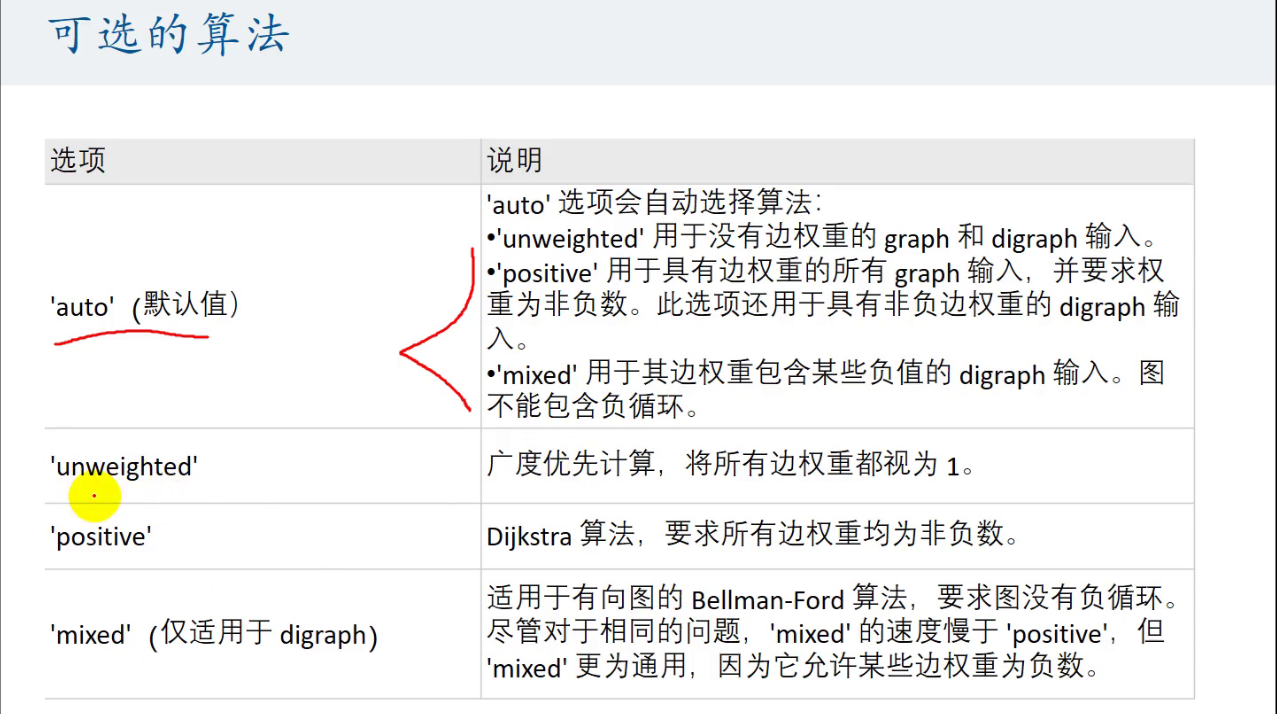
法二:matlab
无权重
1 | |
1 | |
有权重
1 | |
有向图:digraph()
无向图的权重邻接矩阵
有向图的权重邻接矩阵
迪杰斯特拉算法
https://www.bilibili.com/video/BV1q4411M7r9
迪杰斯特拉算法不能处理带有的权重是负数
贝尔曼-福特算法
改进迪杰斯特拉算法
matlab常用函数
shortpath()
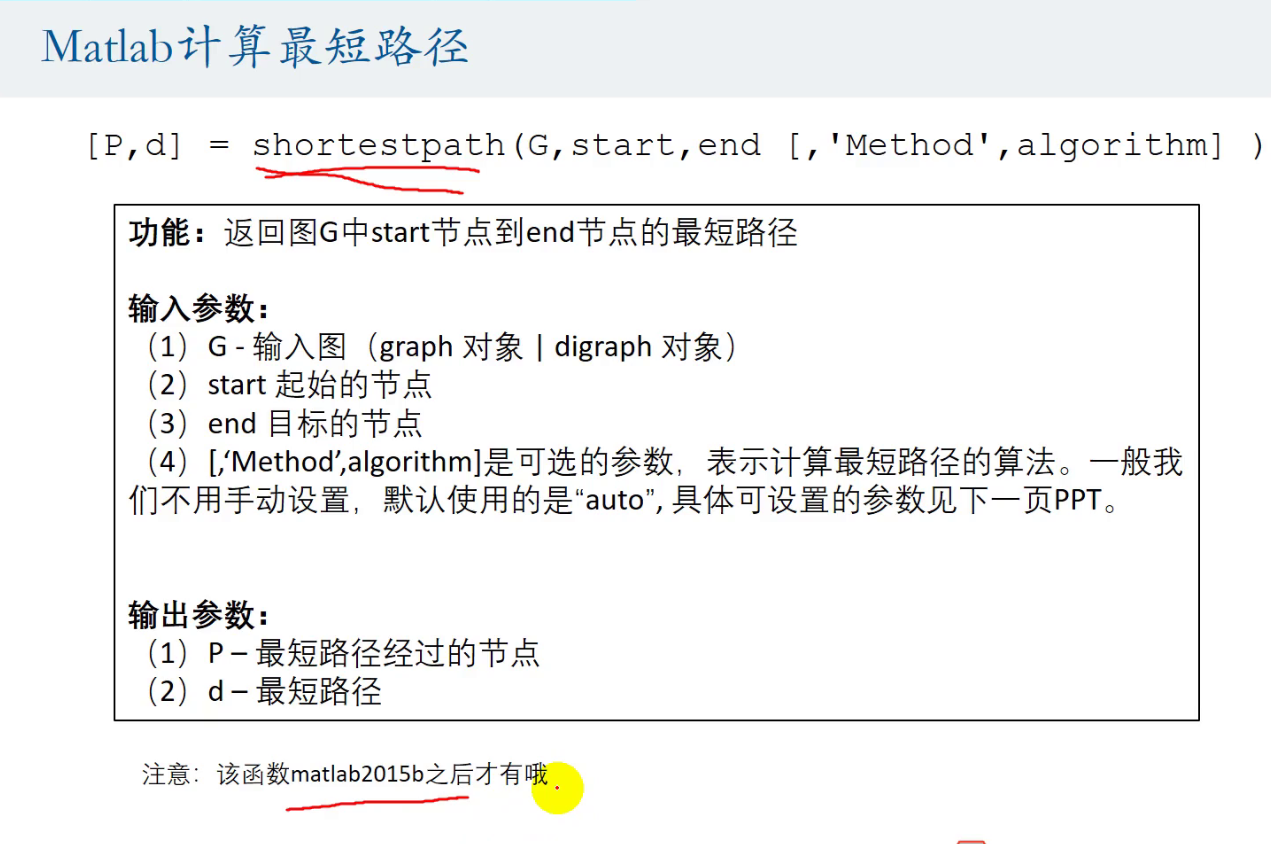
高亮最短路径
1 | |
distances()
返回任意两点的距离矩阵
nearest
找出给定范围内的所有的点
弗洛伊德算法
弗洛伊德算法与迪杰斯特算法或贝尔曼福特算法相比,能够一次性求出任意两点之间的最短路径,后两种算法运行一次只能计算出给定的起点和终点之间的最短路径。
https://www.bilibili.com/video/BV1q4411M7r9
三个循环
1 | |
线性回归分析(没看懂)
常见的回归:线性回归,0-1回归,定序回归,计数回归,生存回归
回归概论
回归的三个关键词
相关性,X,Y
相关性
1
2区分相关性和因果性
通过回归分析,判断相关性Y
1
Y,因变量
X
1
X,自变量
回归分析的使命
1 | |
回归分析的分类
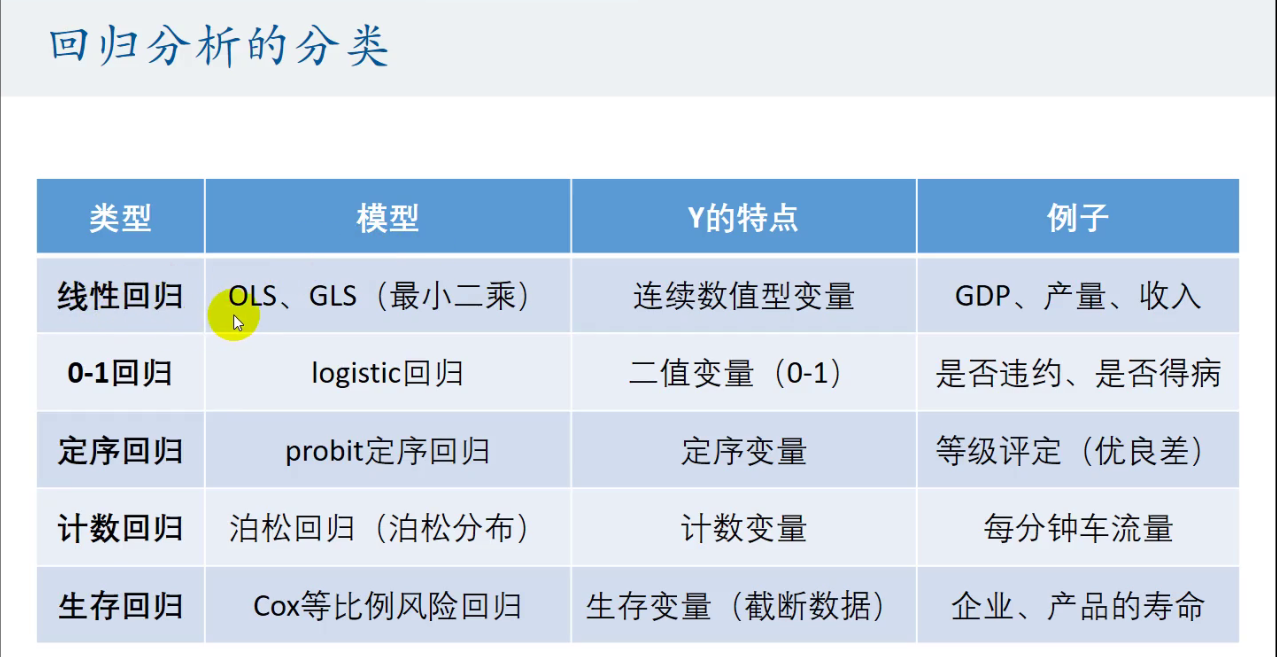
数据的分类以及数据的来源
- 横截面数据:在某一时间点收集的不同对象的数据
- 时间序列数据:对同一对象在不同时间连续观察所取得的数据
- 面板数据:横截面数据与时间序列数据综合起来的一种数据资源
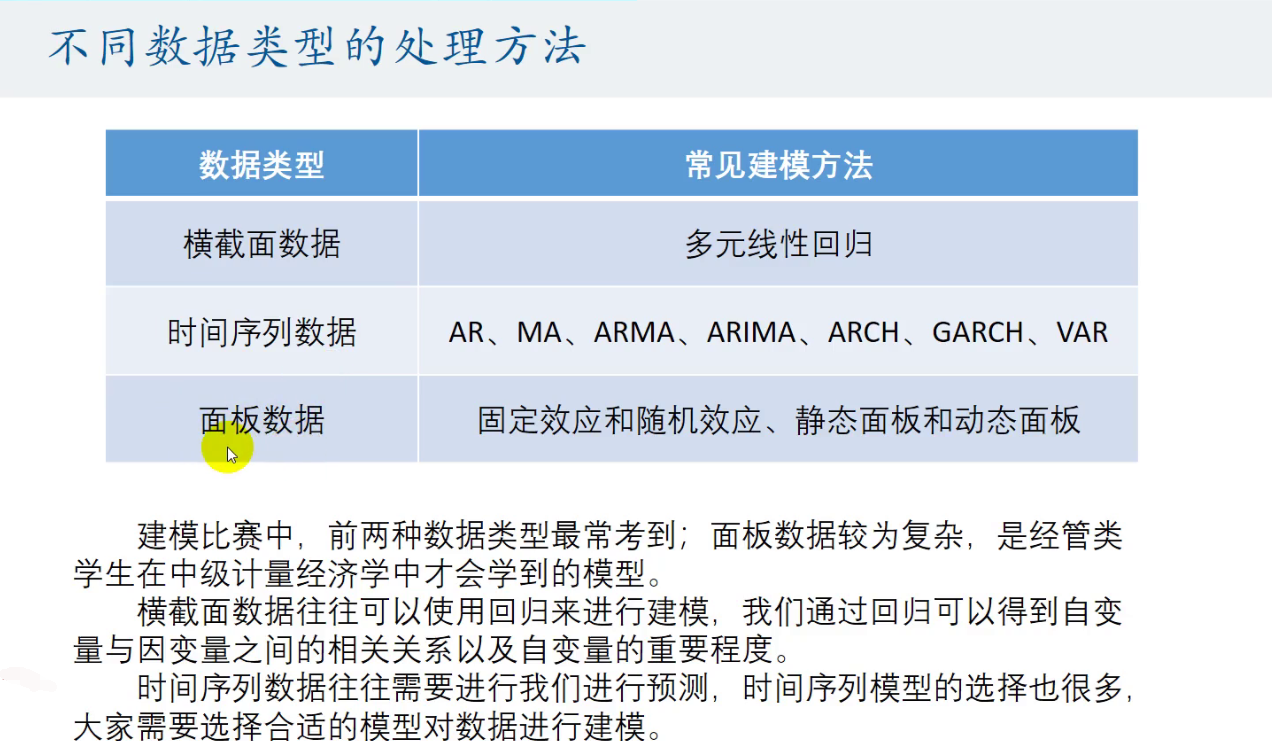
资料的获取
一元线性回归
一元线性函数拟合
一元线性回归模型

遗漏变量导致的内生性
如果满足误差项u和所有的自变量x均不相关,则称该回归模型具有外生性
扰动性:包含了所有与y相关,但未添加到回归模型中的变量
如果这些变量和我们已经添加的自变量相关,则存在内生性
内生性的蒙特卡洛模拟
核心解释变量:我们最感兴趣的变量,因此我们特别希望得到对其系数的一致估计。(当样本容量无限增大时,收敛于待估计参数的真值)
控制变量:我们可能对与这些变量本身并无太大兴趣;而之所以把他们放入到回归方程中,只要是为了“控制住”那些被解释变量有影响的遗漏因素
四种模型的解释
取对数:取对数意味着原被解释变量对解释变量的弹性,即百分比的变化而不是数值的变化



特殊的自变量:虚拟变量X
自变量中的定性变量:性别,地域等
交互效应
回归的应用
使用软件Stata
stata中的计算结果不要直接截图,而是复制到excel表格中,并在excel中调整为三线表,然后粘贴到论文中
1 | |
excel数据透视表:对数据进行交互分析
论文中的问题
- 数据不要归一化
异方差,多重共线性,逐步回归
分类模型
二分类模型和多分类模型
逻辑回归,Fisher线性判别分析
二元逻辑分类
使用SPSS对数据进行预处理
转换-创建虚变量建模
线性概率模型——LPM
直接用原来的回归模型进行回归。
内生性问题:看扰动项是否与自变量相关
1 | |
连接函数,将解释变量x和被解释变量y连接起来,我们只要保证连接函数是定义在[0,1]上的函数,就能保证y_hat符合概率的要求。
连接函数的取法
1 | |

求解方法——因为是非线性模型,使用极大似然估计


- 使用SPSS求解逻辑回归
分析-回归-二元Logistic
因变量:虚变量
协变量:自变量x
分类:协变量->分类协变量,定性变量
保存:概论,组成员
选项:步进概率

逐步回归的设置
分析-回归-二元Logistic
方法:向前,向后
选项:步进,除去假如自变量有分类变量怎么办
1
2
3两种解决方法
- 先创建虚拟变量,然后任意删除一列以排除完全多重共线性的影响;
- 直接点击分类,然后定义分类协变量,SPSS会自动帮我们生成;(推荐方法)解决回归准确率低的问题
可在logistic回归模型中加入平方项,交互项。
回归结果:
虽然预测能力提高了,但容易出现过拟合的现象。如何确定合适的模型
1
2
3
4把数据分为分为训练组和测试组,用训练组的世界来估计出模型,在用测试在的数据进行测试。(训练组和测试组为2:8)
然后比较设置的不同自变量后的模型对于测试组的预测效果。
(注意:为了消除偶然性的影响,可以对上述步骤多重复几次,最终对每个模型求一个平均的准确率,这个步骤称为交叉验证)
Fisher线性判别分析(LDA)
超平面
用超平面将两类样本点分割开SPSS操作
分析-分类-判别式
定义范围:0-1
统计:费希尔,未标准化
分类:摘要表
保存:预测组成员,组成员概率
多分类问题
- Fisher线性判别分析解决多分类问题
1 | |
- 逻辑回归解决多分类问题
将Sigmoid函数推广为Softmax函数就可以将逻辑回归应用到多分类问题
1 | |
聚类模型
聚类是将样本划分为由类似的对象组成的多个类的过程。
分类是已知类别的,聚类是未知的。
K-means聚类算法
算法流程
1 | |
聚类的结果与聚类中心有关

用流程图代替算法的文字描述能有效避免查重
K-means算法的评价
- 优点
- 算法简单,快速;
- 对处理大数据集,该算法三相对高效的。
- 缺点
- 要求用户必须实现给出要生生成的簇的数目K;
- 对初值敏感(初始聚类中心);
- 对于孤立点数据敏感
K-means++算法
选择初始聚类中心的基本原则是:初始的聚类中心之间互相距离要尽可能的远
K-means++可以解决K-means算法的缺点2和3。
1 | |
SPSS操作
分析-分类-K均值聚类
K-means算法的讨论
聚类的个数怎么选择?——根据个人经验与感觉
数据的量纲不一致怎么解决?——标准化(将每个数据先减去其均值再除以标准差)
- SPSS软件能自动计算
分析-描述统计-描述,将标准化值另存为变量
系统(层次)聚类
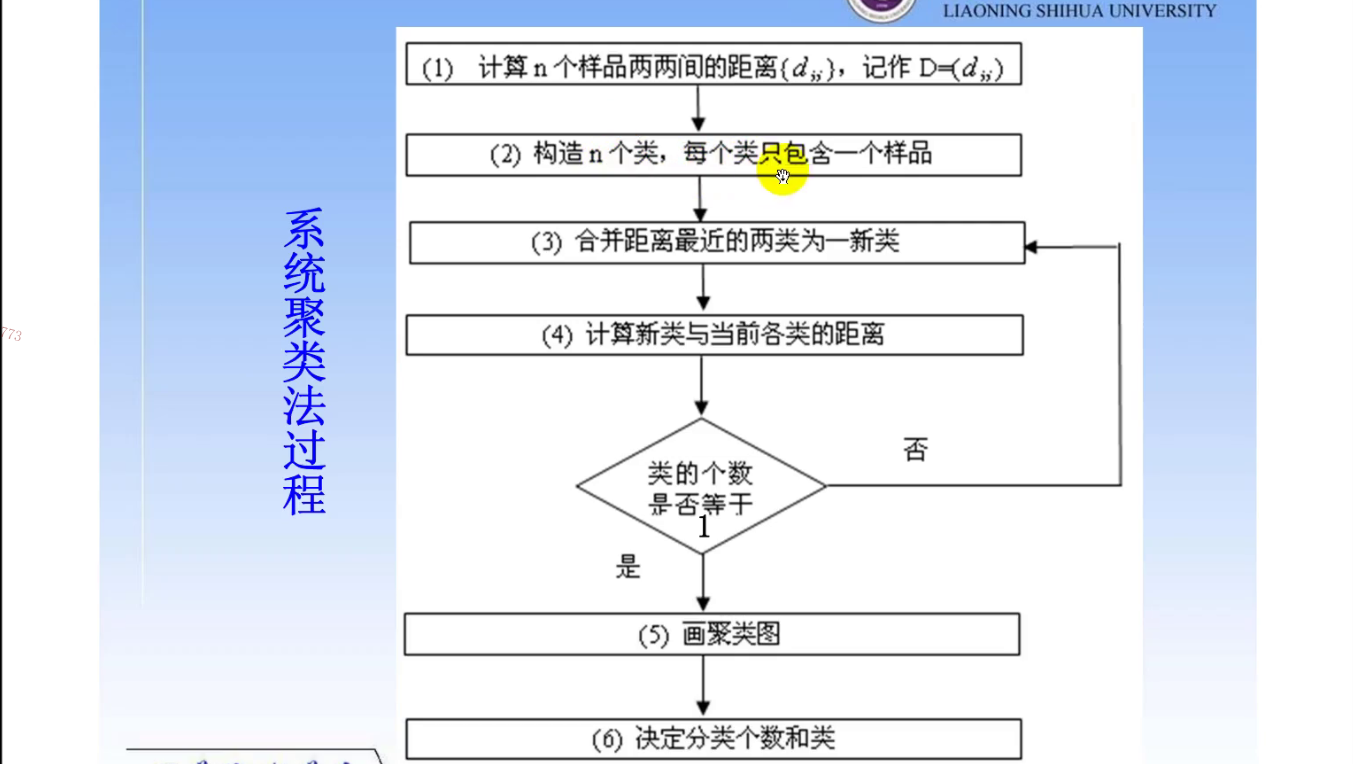
系统聚类的合并算法通过两类数据点间的距离,对最为接近的两类数据点进行合并,并反复迭代这一过程,直到将所有数据点合并成一类,并生成聚类谱系图。
样品与样品之间的常用距离

绝对值距离:网状道路
欧式距离:不使用绝对值距离则一般就使用欧式距离。
类与类之间的距离

聚类方法
最短距离法

组间平均连接法(使用得更多)

组内平均连接法(使用得更多)

重心法

系统聚类的过程
聚类分析需要注意的问题
- 对于一个实际问题根据分类的目的来选取指标,指标选取的不同分类结果一般也不同;
- 样品间距离定义的方式不同,聚类结果一般也不同;
- 聚类方法的不同,聚类结果一般也不同(尤其是样品特别多的时候)。最好能通过各种方法找出其中的公性。
- 要注意指标的量纲,量纲差别太大会导致聚类结果不合理;
- 聚类分析的结果可能不令人满意,因为i我们所作的是一个数学的处理,对于结果我们要找到一个合理的解释。
系统(层次)聚类算法流程
- 将每个对象看作一类,计算两两之间的最小距离;
- 将距离最小的两个类合并成一个新类;
- 重新计算新类与所有类之间的距离;
- 重复2和3,直到所有类最后合成一类;
- 结束
(自己绘制出流程图——避免查重)
SPSS操作步骤
分析-分类-系统聚类
图:谱系图

肘部法则——确定最优的K值

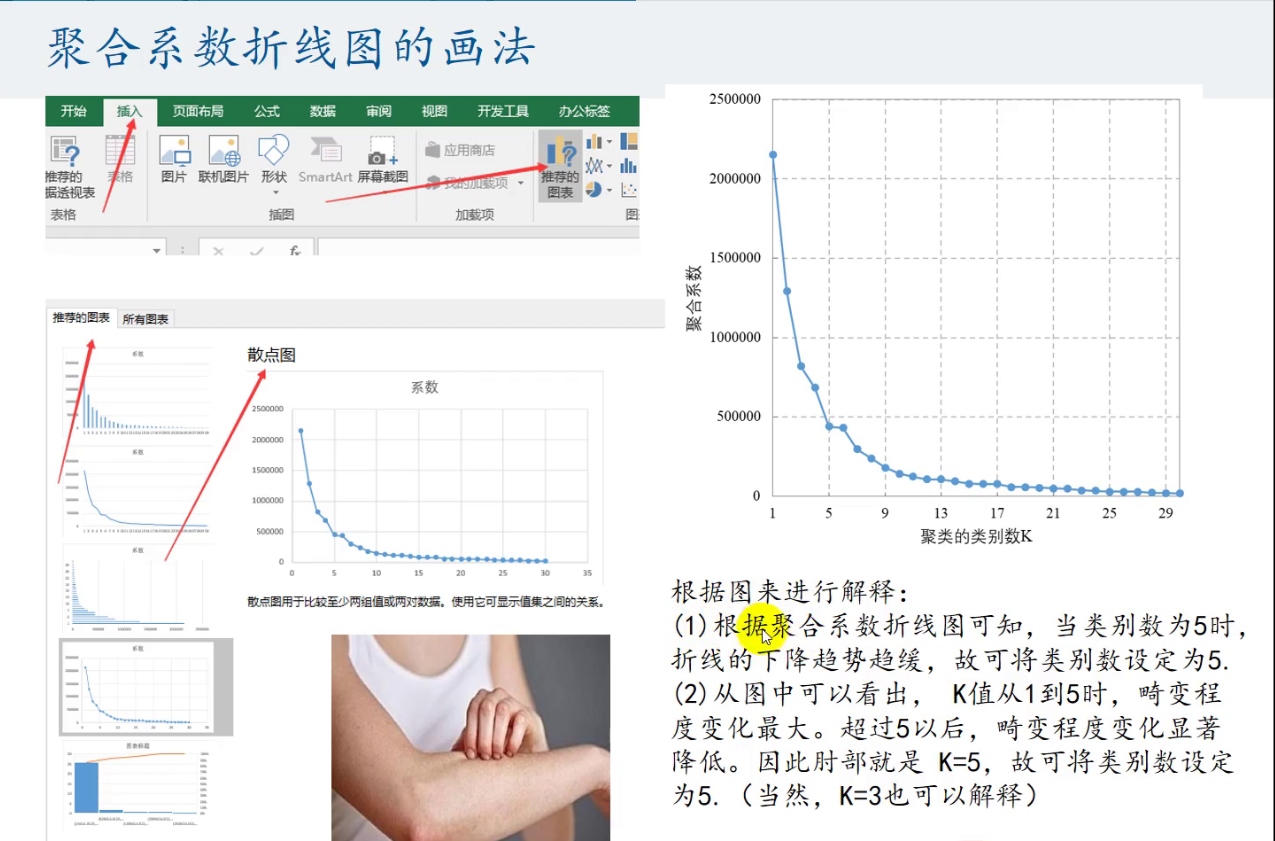

确定K之后保存聚类结果并画图只能有两个或三个变量,绘制二维或三维图
DBSCAN算法
具有噪声的基于密度的聚类算法
聚类前不需要预先指定聚类的个数,生成的簇的个数不定
DBCAN算法将数据点分为三类
核心点
边界点
噪声点
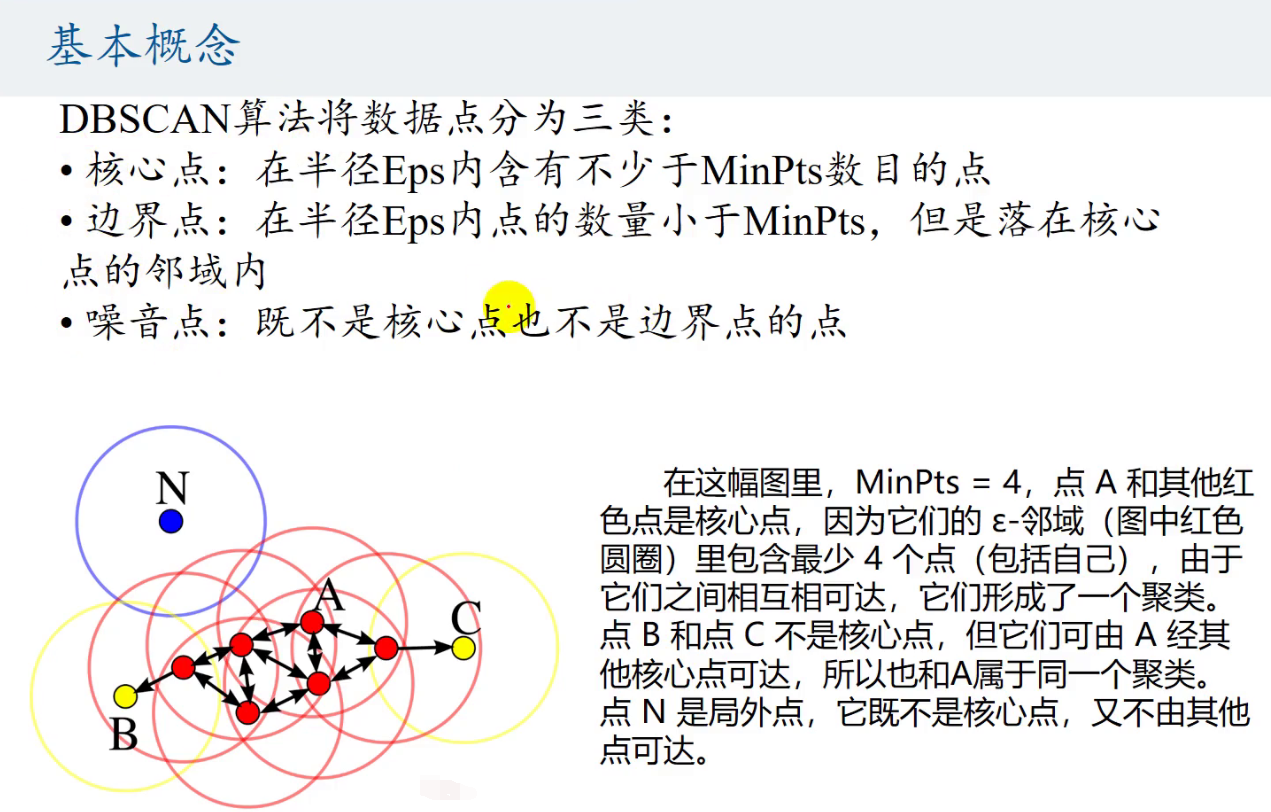
使用matlab对算法进行实现
只有两个指标,且做出的散点图有明显的密度差距,这时候用DBSCAN算法,否则使用另外的聚类算法。
时间序列分析
时间序列也称为动态序列,是指将某种现象的指标数值按照时间顺序排列而成的数值序列。
时间序列大致可以分为三大部分:描述过去,分析规律,预测未来
三种模型:季节分解,指数平滑,ARIMA模型
主要使用SPSS软件
基本定义
时间序列数据:对同一对象在不同时间连续观察所得到的数据。
时间序列的组成要素:时间要素,数值要素
时间序列的分类:时期时间序列,时点时间序列
时期序列:数值要素反映现象在一定时期内发展的结果;
时点序列:数值要素反映现象在一定时点上的瞬间水平;
时期序列可加,时点序列不可加
时间序列分解
一般情况下,时间序列的数值变化规律有四种:长期变动趋势,季节变动规律,周期变动规律,不规则变动(随机扰动项)。
- 长期趋势T:人均收入,新生儿的死亡率;
- 季节趋势S:周期性:以月份,季度,周为单位
清风推荐网站:百度指数https://index.baidu.com/v2/index.html#/ - 循环变动C:以若干年为单位:商业周期,经济周期
- 不规则变动I:扰动项
时间序列分解的结果可能是四种变化规律都有,也可能是只有其中几个;
四种变动与指标数值变动的关系可能是叠加关系,也可能三乘积关系
叠加模型和乘积模型
1 | |

SPSS软件使用步骤
- SPSS处理时间序列中的缺失值
- 缺失值发生在时间序列的开头或者结尾,可采用直接删除的方法;
- 缺失值发生在序列的中间位置,则不能删除,可采用替换缺失值的方法。
替换缺失值的五种方法:
1 | |
SPSS:转换-替换缺失值
SPSS软件定义时间变量
数据-定义日期和时间时间序列图
分析-时间序列预测-序列图季节性分解
分析-时间序列预测-季节性分解
SPSS statastic 25 没有这个选项??
时间序列分析的步骤

值数平滑方法
专家建模器
Simple模型
名称:简单指数平滑法
适用条件:不含趋势和季节成分
与之类似的ARIMA模型:ARIMA(0,1,1)
只能预测一期的值,这是由于公式所决定的
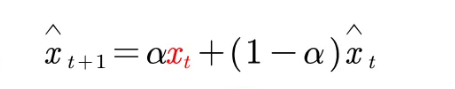
线性趋势模型
名称:霍特线性趋势模型
使用条件:线性趋势,不含季节成分
与之类似的ARIMA模型:ARIMA(0,2,2)

阻尼趋势模型
名称:阻尼趋势模型
使用条件:线性趋势逐渐减弱且不含季节成分
与之类似的ARIMA模型:ARIMA(1,1,2)

简单季节性模型
名称:简单季节性
适用条件:还有稳定的季节成分,不含趋势
与之类似的ARIMA模型:SARIMA(0,1,1)*(0,1,1)_s

温特加法模型
名称:温特加法模型
适用条件:含有线性趋势和稳定的季节成分
与之类似的ARIMA模型:SARIMA(0,1,0)*(0,1,1)_s

温特乘法模型
名称:温特加法模型
适用条件:含有线性趋势和不稳定的季节成分
与之类似的ARIMA模型:不存在

ARIMA模型
差分自回归移动评价模型
ARIMA(p,d,q)
SARIMA模型
季节性ARIMA模型
实例
建模思路

预测模型
灰色预测模型
神经网络在数据预测中的应用
灰色预测模型
1 | |
- GM(1,1)模型:Grey Model
GM(1,1)是使用原始的离散非负数据列,通过一次累加生成削弱随机性的较有规律新的离散数据列,然后通过建立微分方程,得到在离散点处的解经过累计生成的原始数据的近似估计值,从而预测原始数据的后续发展
GM(1,1),前一个1表示1阶微分方程,后一个1表示只有一个变量
准指数规律检验
1 | |
GM(1,1)模型的评价
检验模型对原始数据的拟合程度(对原始数据还原的效果)。一般有两种检验方法:
残差检验

级比偏差检验

什么时候使用灰色预测
- 数据是以年份度量的非负数据(如果是月份或者季度数据,则用时间序列模型)
- 数据能经过准指数规律的检验(除了前两期外,后面至少90%的期数的光滑比要低于0.5)
- 数据的期数较短且和其他数据之间的关联性不强(小与10期,但也不能太短),要是数据期数较长,一般使用传统的时间序列模型比较合适。

GM(1,1)模型代码讲解
大概的步骤
1 | |
BP神经网络预测

基本概念:
训练集(Training Set):用于模型拟合的数据样本
验证集(Validation Set):是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进学校初步评估。在神经网络中,我们用验证数据集取寻找最优的网络深度,或者反向传播算法的停止点或者在神经网络中选择隐藏层神经元的数量;
测试集(Testing Set):用来评估模型的泛化能力。不能作为调参、选择特征等算法相关的选择的依据。
使用matlab的BP神经网络
APP-Neural Net Fitting
三种训练网络

Matlab三维图形绘制
matlab绘制三维图形
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
Matlab 符号运算
Matlab定义符号变量和简单的运算
简单符号变量的创建
1
2syms x
syms a b c符号方程的创建
1
2
3
4
5% 法1
syms a x
y=a*x+x^2
% 法2
y=str2sym('a*x+x^2')符号矩阵
简单运算
符号表达式的整理
1
2
3
4
5
6
7化简:simplify(y)
因式分解:factor(y)
多项式展开:expand(y)
多项式合并:collect()
计算分子与分母:numden(符号变量)
把double类型的变量转化为符号变量:sym(double类型的变量)
让结果显示的更加自然:mupad:2020版本不能用了,可以建立一个实时脚本,然后把要看的内容复制到实时脚本,然后运行就行了
符号函数求导和差分的计算
一元函数求导
1
2
3
4syms x
y=x^4+5*x+2
diff(y) 一阶导数
diff(y,2) 二阶导数多元函数求导
1
2
3
4
5diff(y,x,2)
diff(y,x)
diff(y,z)
diff(y,x,z)
diff(y,z,x)差分
如果diff函数的作用对象不是符号函数,而是矩阵的时候,那么对应的功能是求差分
不定积分和定积分的计算
不定积分
int(y,x)
计算结果不会给我们加上常数C
计算1/x的不定积分,结果不会加上绝对值定积分
int(y,x,下限,上限)数值积分——近似积分
数值积分,用于求定积分的近似值。在数值分析中,数值积分是计算定积分数值的方法和理论。在数学分析中,给定函数的定积分的计算不总是可行的。许多定积分不能用已知的积分公式得到精确值。
数值积分是利用黎曼积分等数学定义,用数值逼近的方法近似计算给定的定积分值。借助于电子计算设备,数值积分可以快速而有效地计算复杂的积分
函数y需要写成函数句柄的形式,使用点乘和点除
integral(y,下限,上限)
求解方程和方程组
solve函数
注意周期函数求解的时候需要加上条件,才能得到所有的解vpasolve函数
求指定区间上的解
vpasolve(y,x,[0 1])fsolve函数
微分方程模型
常微分方程+偏微分方程
对常微分方程进行建模

基本概念

微分方程的建立:利用专业知识+套用现有的模型(改进)
使用Matlab求微分方程的解析解
解析解:给出解的具体表达式
matlab函数:dsolve(‘方程1’,’方程2’,……,’方程n’,’初始条件’,’自变量’)
注意
1 | |
1 | |
使用Matlab求微分方程的数值解
更新15第5部分
2022美赛备战
2022年数学建模美赛备战参考——数学建模清风_哔哩哔哩_bilibili
题目分析
MCM(数学建模竞赛):A,B,C
ICM(交叉学科竞赛):D,E,F
MCM要求更深的数学功底和变成基础
ICM要求写作和逻辑能力
A:连续型
B:离散型
C:数据挖掘
D:运筹学和网络科学
E:环境科学
F:政策相关的题目
EF
E,F是最简单的题目,题目要求我们自己收集数据,用到的模型:评价类模型,相关性分析,回归分析,拟合;
E,F比较开放,题目中的小问比较多,因此需要重视写作,论文的结构要求清晰
美赛不需要提交数据和代码
1 | |
D
D题题目固定,涉及到图论,网络分析,优化问题
2020,2021:网络科学
matlab:centrality函数
python:networkx
网络结构可视化软件:gephi——https://gephi.org/
运筹学:排队论,图论,选址优化
C
数据挖掘类题目,根据提供的数据分析出结论
回归分析,时间序列分析,传统机器学习模型
近年来出现了深度学习:2020自然语言处理,2021图像分类
深度学习:B站李沐——https://space.bilibili.com/1567748478
机器学习:https://www.bilibili.com/video/BV1v64y1B7vJ
A B
A——连续
问题中的变量因素是连续变化的,如温度,时间等
B——离散
问题中的变量因素是离散变化的,如数量
连续:微分方程
离散:差分方程
A和B可能会出现一道物理题目,涉及到热力学,流体力学,信号处理
B题目:可能是离散型优化问题,即组合优化问题——智能算法:遗传算法,模拟退火算法
A,B,D可能会用到元胞自动机模型(多主体建模),使用Netlogo仿真模拟软件
常用模型和算法
数学建模竞赛常考三大模型及十大算法_哔哩哔哩_bilibili
三大模型
预测模型(中等难度)
神经网络预测、灰色预测、拟合插值预测(线性回归)、时间序列预测、马尔科夫链预测、微分方程预测、Logistic 模型等等。
应用领域:人口预测、水资源污染增长预测、病毒蔓延预测、竞赛获胜概率预测、月收入预测、销量预测、经济发展情况预测等在工业、农业、商业等经济领域,以及环境、社会和军事等领域中都有广泛的应用。
优化模型(偏难)
规划模型(目标规划、线性规划、非线性规划、整数规划、动态规划)、图论模型、排队论模型、神经网络模型、现代优化算法(遗传算法、 模拟退火算法、蚁群算法、禁忌搜索算法)等等。
应用领域:快递员派送快递的最短路径问题、水资源调度优化问题、高速路 口收费站问题、军事行动避空侦察的时机和路线选择、物流选址问题、商区布局规划等各个领域。
评价模型(偏简单)
模糊综合评价法、层次分析法、聚类分析法、主成分分析评价法、 灰色综合评价法、人工神经网络评价法等等。
应用领域:某区域水资源评价、水利工程项目风险评价、城市发展程度评价、足球教练评价、篮球队评价、水生态评价、大坝安全评价、边坡稳定性评价
十大算法
蒙特卡洛算法
又称为随精选模拟算法,
是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,是比赛时,必用的方法数据处理算法
数据拟合,参数估计,插值等:
比赛在通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用matlab作为工具规划类问题算法
线性规划,整体规划,多元规划,二次规划等规划类问题:
建模比赛中大数问题属于最优化问题,很多时候这些问题可以用数学规划算法来解决,通常使用Lindo,Lingo等软件实现图论算法
最短路径,网络流,二分图等算法动态规划,回溯搜索,分治算法,分支定界
最优化理论三大经典算法
模拟退火算法,遗传算法,神经网络网格算法,穷举法
连续离散化方法
数值分析算法
图像处理算法
美赛论文写作
数学建模清风——论文写作方法教程(国赛和美赛)_哔哩哔哩_bilibili
MCM: The Mathematical Contest in Modeling (comap.com)
2022 Contest Dates and Times:
Registration Deadline: Before 3:00 p.m. EST on Thursday, February 17, 2022.
Contest Starts: 5:00 p.m. EST on Thursday, February 17, 2022.
Contest Ends: 8:00 p.m. EST on Monday, February 21, 2022.
Solution Report Deadline: 9:00 p.m. EST on Monday, February 21, 2022.
Contest Results: The results will be posted on or before May 20, 2022.
2022美赛的关键时间节点报名截止时间 美国东部时间2022年2月17日 15:00之前(星期四) 北京时间2022年2月18日 凌晨4:00之前(星期五)
比赛开始时间 美国东部时间2022年2月17日 17:00(星期四) 北京时间2022年2月18日 上午6:00(星期五)
比赛截止时间 美国东部时间2022年2月21日 20:00(星期一) 北京时间2022年2月22日 上午9:00(星期二)
提交方案截止时间 美国东部时间2022年2月21日 21:00(星期一) 北京时间2022年2月22日 上午10:00(星期二)
比赛结果公布时间 美国东部时间2022年5月20日之前发布

Summary Sheet 摘要页(超级重要)
布局
1 | |
1 | |
不能超过一页,读者在不阅读全文的情况下,就能获得必要的信息
摘要包含的三要素:解决了什么问题,应用了什么方法, 得到了什么结果
概括全文,行文简洁,突出论文的新见解,新方法和特色,不能有主观性
摘要是其他部分都写完之后,再来书写(半天时间)
- 摘要的开头段
三句话,三到五行
第一句话简单交代题目的背景(可选)
第二句话交代你们所作的事情(最重要)
第三句话说以先解决这个问题的实际意义(少部分论文有)
- 摘要的中间段
解决了什么问题,应用了什么方法, 得到了什么结果
- 解决了什么问题:不单独提出我们要解决的问题,因为后面的两个要素会提到
- 应用了什么方法:紧扣题目
- 得到了什么结果:

- 摘要的结尾段
介绍论文的亮点,对类似问题进行适当的推广
如果不会写的话,可以不写结尾段
- 不要出现的废话

- 论文的标题title和关键词key world
标题和关键词要求不严格

Contents 目录
目录快速生成——排版课程
正文1 Introduction 引言
引言包含了两到三个小部分
- Problem Background 问题背景
总结题目所给的背景
结合自己对赛题的理解,讲背景介绍有侧重的往自己研究的方向去靠
Restatement of the Problem 问题重述
1和2可以合并为一点
Literature Review 文献综述
这部分主要是总结以前的学者针对这个问题已经做的研究。事实上,绝大多数期刊发表的论文都会有文献综述部 分。但在美赛特等奖论文中,只有不到30%的论文有这一部分,不是说这部分不重要,而是这一部分很难写。
注意:文献综述本身就是一种文体,可以作为论文独立发表,也可以放在论 文中作为独立的一个部分;我们在美赛中写的文献综述不需要达到上面定义写的
这么严格的标准。
总结写作特点: 有很多学者都研究过这个问题(红色圈出来的编号就是参考文献的标记),其中:
某某学者建立了某某模型或者使用了某某方法研究了这个问题;
某某学者通过研究了这个问题得到了某某结论。
技巧:文献综述中的文章能直接和你的论文中使用的模型或者得到的结论相互呼应!
- Our work 我们的工作
大家如果看特等奖论文的话,会发现很多论文在这 一部分都绘制了一个漂亮的图形来介绍文章的思路,大
家可以模仿模仿。
正文2 Assumptions and Justifications 模型假设
美赛要求较高

正文3 Notations 符号说明


正文4 5 6 模型的建立与求解(正文最重要的部分)
模型建立:模型建立是将原问题抽象成用数学语言的表达式,它一定是在先 前的问题分析和模型假设的基础上得来的。因为比赛时间很紧,大多时候我们都是 使用别人已经建立好的模型。这部分一定要将题目问的问题和模型紧密结合起来, 切忌随意套用模型。我们还可以对已有模型的某一方面进行改进或者优化,或者建 立不同的模型解决同一个问题,这样就是论文的创新和亮点。
模型求解:把实际问题归结为一定的数学模型后,就要利用数学模型求解所 提出的实际问题了。一般需要借助计算机软件进行求解,例如常用的软件有Matlab, Spss, Lingo, Excel, Stata, Python等。求解完成后,得到的求解结果应该规范准确并且 醒目,若求解结果过长,最好编入附录里。(注意:如果使用智能优化算法或者数值计算方法求解的话,需要简要阐明算法的计算步骤)
每个模型作为一个单独的大标题
而美赛的命名方式五花八门,有些 论文使用建立的模型的名称命名;有些使用论文要解决 的问题命名;也有些论文使用和国赛一样简单粗暴的方
式命名。

可以以要解决的问题命名也可以以求解问题命名
明确题意后,简述基本思路。首先,简要介绍利用的基本原理和基本思 想,再进行构建基本模型,如数学表达式、算法流程图等,要明确说明解题 的思想和思路,有逻辑性、合理性、可行性,需要完整叙述。也可以结合实 际问题,进行改进和完善基本模型,使其能有效、实用解决问题。
三点要求:
- 必须要有数学模型:即数学公式组成的一套数学结构、或者是一套 数学的解决方案等;
- 模型要求表达完整,正确和简明;
- 模型要有实用性,要能求解出来,以能够解决问题为原则。
模型求解的注意事项:
1)国赛中常出优化类问题,如果你用到了启发式算法求解的话,一定要简 要写明算法步骤,并要结合具体的问题来阐明计算的思路。
2)求解的结果应该在论文中突出的展示出来,有具体答案的问题比较简单, 直接放上数值计算结果即可;如果是开放类问题的话,一定要对结果进行阐明
和解释,如果能加上美观整洁的图表就更好了。
正文 Data Description 数据描述(不常见)
Data Description翻译过来就是数据描述。注意,这部分内容不是必须 的,大家根据自己的需要来进行添加。
如果自己收集了数据或者题目给了数据的话,可以先对数据进行一个 简单的介绍,或者将数据可视化,然后再从图形中得到一些直观的结论。
这里给大家一些相关的术语的翻译:• Data Collection(数据的收集)
• Data Pre-processing(数据预处理) / Data Cleaning(数据清洗)
• Data Visualization(数据可视化)
• Descriptive Statistical Analysis of the Data(数据的描述性统计分析)
这部分内容在论文中的位置也比较灵活,我们可以将这个内容放到模型的建立与求解中,也有部分论文放在了引言部分,还有的论文将这个内容放到“Model Preparation模型准备”这个部分,这种见得比较少,我们之前 在国赛论文框架中介绍过模型准备的写法。特别的,如果做的是美赛C题 (C题一般是数据分析类型的题目),我们可以把这个部分单独作为一个大的部分,然后进行数据预处理和数据可视化分析。
正文7 Sensitivity Analysis 灵敏度分析(重要)(不是很懂)
数学建模中的灵敏度分析,到底在分析什么? - 知乎 (zhihu.com)
在这个部分中,我介绍了灵敏度分析、误差分析和稳定性检验的写法, 其中稳定性检验和灵敏度分析非常类似,因此大家要掌握的就是前面两种分 析的写法。
在美赛的写作中,写的最多的就是灵敏度分析,因此这里我们的标题就直接取得是Sensitivity Analysis; 如果你既要写灵敏度分析,又要写误差分析, 那么你可以把标题改成: Sensitivity Analysis and Error Analysis. 注意: • 误差分析一般翻译为:Error Analysis • 稳定性检验的别称较多,还可以称为稳健型检验或稳健型分析,因此它的翻译也较多,可翻译为:Stability Test、 Robustness Test或者Robustness Analysis
模型的分析 :在建模比赛中模型分析主要有两种,一个是灵敏度(性)分析, 另一个是误差分析。灵敏度分析是研究与分析一个系统(或模型)的状态或输出 变化对系统参数或周围条件变化的敏感程度的方法。其通用的步骤是:控制其他 参数不变的情况下,改变模型中某个重要参数的值,然后观察模型的结果的变化 情况。误差分析是指分析模型中的误差来源,或者估算模型中存在的误差,一般 用于预测问题或者数值计算类问题。
模型的检验:模型检验可以分为两种,一种是使用模型之前应该进行的检验,例如层次分析法中一致性检验,灰色预测中的准指数规律的检验,这部分内容应该放在模型的建立部分;另一种是使用了模型后对模型的结果进行检验,数模中 最常见的是稳定性检验(有的论文也称为稳健型检验或稳健型分析),实际上这里的稳定性检验和前面的灵敏度分析非常类似,等会大家看到例子就明白了。


正文8 Model Evaluation and Further Discussion 模型的评价和进一步的讨论
该部分可以翻译为模型的评价和进一步的讨论,对应于国赛框架中的模 型的评价、改进与推广部分
我们可以把这个大的部分拆分成三个小部分写:
(1)Strengths 这里写论文或者模型的优点
(2)Weaknesses 这里写缺点:缺点写的个数一般要比优点少
(3) Further Discussion 进行进一步的讨论,这里可以写模型的改进和拓展。
模型改进:Model Improvements 模型拓展:Model Extensions
(这里单词写的都是复数形式,如果你只写了一点就改成单数形式)
另外,本部分的标题需要根据你的内容进行调整,例如:如果你没有写进一步讨论的话,就直接把标题写成模型的评价Model Evaluation 。
正文9 Conclusion 结论
Conclusion翻译过来就是结论,这个部分在国赛论文几 乎见不到,但在美赛中出现的频率很高。
这个部分可以是论文中心思想的重申、研究结果或主要 观点的归纳,也可以是某些启示性的解释或考虑。
有些论文把“Model Evaluation and Further Discussion”的 内容放到了结论部分.

注意区分这三个部分!!!!!!

References 参考文献
本部分是参考文献,在美赛中,参考文献不要出现中文! 如果要引用中文论文或者书籍怎么办?请自己翻译
Appendices 附录
附录中的代码也不要出现中文注释,也就是任何地方都不要出现中文

Article 杂志文章
美赛有些题目会要求大家给某个杂志写一篇文章(Article)
(1)2020A题 In addition to your technical report, prepare a one- to two-page article for Hook
Line and Sinker magazine to help fishermen understand the seriousness of the problem and how your proposed solution(s) will improve their future business prospects.除了你的技术报告,准备一到两页的文章,作为Hook Line and Sinker 的杂 志内容,以帮助渔民了解问题的严重性,以及你的解决方案将如何改善他们未 来的业务前景。
(2)2020B题 Finally, write an informative, one- to two-page article describing your model and
its results for publication in the vacation magazine: Fun in the Sun, whose readers are mainly non-technical.
最后,写一篇内容丰富的一到两页的文章,描述你的模型及其结果,发表
在假期杂志上:Fun in the Sun ,读者都是小白,不懂太复杂的模型。文章中不要写太过专业的话,确保你的读者能读得懂!


Letter 写信

Memo 备忘录


美赛论文排版
LaTex学习成本太大了,因此使用Word进行排版。
优秀论文共同特点:
(1)整体结构完整,大多数论文都是使用三级标题式进行布局;
(2)论文正文部分排版紧凑,没有大段空行,内容看上去翔实;
(3)表格整洁,一般使用三线表形式,表格上方有对应的标题;
(4)图形清晰美观,下方有对应的标题,文中要解释图形意义;(表上图下)
(5)公式编辑规范,大部分论文使用公式编辑器,且带有编号。
Word 基础知识
F4键的作用是重复上一步操作,在PPT和Excel中也是同样的作用。
首行缩进不要打两个空格,应该在开始-段落中设置首行缩进
Ctrl+Enter:分页符
Delete:大多数时候我们删除某个内容使用的都是退格键,但有时候排版的时候,你会发现使用退格键删除后论文的排版格式乱掉了(特别是有表格需要排版的时候用的很多),这时候可以考虑使用删除键。我们以后遇到了再来给大家强调这一点。
格式刷:先复制需要的格式,然后点击格式刷,点击格式刷一次,只能进行一次格复制,点击两次能进行无数次格式复制
左对齐,居中对齐,右对齐,两端对齐,分散对齐
项目符号,编号,多级列表
样式和多级列表
引用-目录:插入目录
论文模板
1 | |
表格的制作和排版
三线表
使用边框刷子:点顶线:1.5磅;栏目线:0.75磅;底线:1.5磅
文字:水平居中
分布行,分布列:把表格的行和列都变成一样大小
制作三线表的模板
长表格的处理:excel预处理
宽表格的处理:excel预处理
两个并排的独立表格:excel预处理
有合并单元格的表格:先用excel预处理,断点用白色的边框替代
Stata的回归结果表格:
SPSS输出的表格:
文章或报告的封面:
自动生成表的标题:选中表格-引用-插入题注
文章的内容与表格相关联,如:结果请见表2,引用-交叉引用
Ctrl+A,全选,然后按F9,可以刷新整篇文章
文字与表格或者图像之间的间距可以设置为0.5行
图形的制作和排版
国赛中的图要求简约
美赛中的图要求美观,吸人眼球
图片首先设置无缩进,然后居中对齐,再在图片下边写上编号和图片的标题
(记住:表上图下,即表的标题在上面,图的标题在下 面)
图片的制作
- matlab或者python
- excel,spss,origin
- 展示模型或者算法过程的流程图
- 描述问题分析或者建模思路的示意图
使用PPT绘制思维导图——SmartArt
Xmind

绘制带用矢量图的示意图——阿里巴巴矢量图库,Islide矢量图插件,Draw.io
对图像的加工——PPT等
流程图的绘制:Draw.io
物理示意图的绘制:PPT,AxGraph(有水印)
社会网络图
- 手动:Gelphi,yEd - Graph Editor (yworks.com)
- python的nerworkx包
地理数据可视化GIS——经纬度可视化
- 专业:ArcGIS,MapGIS,supermap
- Tableau,Power BI
- python的folium包
使用Excel地图数据可视化——中国和美国的地图都有了
对任意国家的地图进行可视化设计:Pixel Map Generator | amCharts(中国地图有问题)
图例,用PPT中的表格

公式的编辑和排版
LaTex:在线LaTeX公式编辑器-编辑器 (latexlive.com)
【老湿基】为妈咪叔 LaTeXLive.com 网页程序打call|侠之大者,为国为民!_哔哩哔哩_bilibili
Word自带的公式编辑器:alt和=同时按下
AxMath:免费部分功能
MathTpye:收费
将公式识别为LaTex代码:Mathpix Snip,Mathpix每个月能免费用50次
在线LaTeX公式编辑器-编辑器 (latexlive.com):也可以进行公式的识别
AxMath:


公式的自动编号
行内公式
行间公式——编号


插入公式时候出现的问题
- 公式上浮问题
选中段落,右键-段落-中文版式-将文本对齐方式改为居中-确定
- 公式的间距过大——行内公式
选中段落,右键-段落-取消勾选下面的这两个框

- 公式编辑器中不要出现中文
参考文献的排版
要求:所有引用他人或公开资料(包括网上资料)的成果必须按科技论文的规范 列出参考文献,并在正文引用处予以标注(引用-交叉引用)。
1 | |


附录的排版

代码高亮:代码在线高亮工具 | 将高亮美化的代码一键粘贴到 Word 或 OneNote 中 (highlightcode.com)
CodeInWord|在word中优雅展现的代码|代码高亮|word中插入代码|代码格式化
Ubuntu Pastebin——支持Matlab


美赛论文排版要求


目录过长,目录页超过了一页,可以把显示级别设置为2
用表格设置并排的图片
表格的嵌套

英文段字效果

机器学习
数学建模清风第四次直播:利用matlab快速实现机器学习_哔哩哔哩_bilibili
资料——提取码:kkkk
基本概念和分类
机器学习:
书中对于机器学习的一个定义:
机器学习正是这样一门学科,它致力于研究如何 通过计算的手段,利用经验来改善系统自身的性能.在计算机系统中,“经验”通常以 “数据”形式存在,
因此,机器学习所研究的主要内容,是关于在计算机上从数据中产 生“模型”(model)的算法,即“学习算法”(learning algorithm).
有了学习算法,我 们把经验数据提供给它,它就能基于这些数据产生模型;在面对新的情况时(例如看到一个没剖开的西瓜),模型会给我们提供相应的判断(例如好瓜).

机器学习:监督学习(supervised learning),无监督学习(unsupervised learning),强化学习(reinforcement learning),半监督学习(semi-supervised learning),主动学习(active learning)
监督学习
监督学习是指从标注数据中学习预测模型的机器学习问题。标注数据表示输入输出的对应关系,预测模型对给定的输入产生响应的输出。监督学习的本质是学习输入到输出的映射统计规律。
翻译成白话:我们的数据既有输入变量又有输出变量(既有特征 feature 又有标签 label),我们要找到输入变量和输出变量之间的关系。
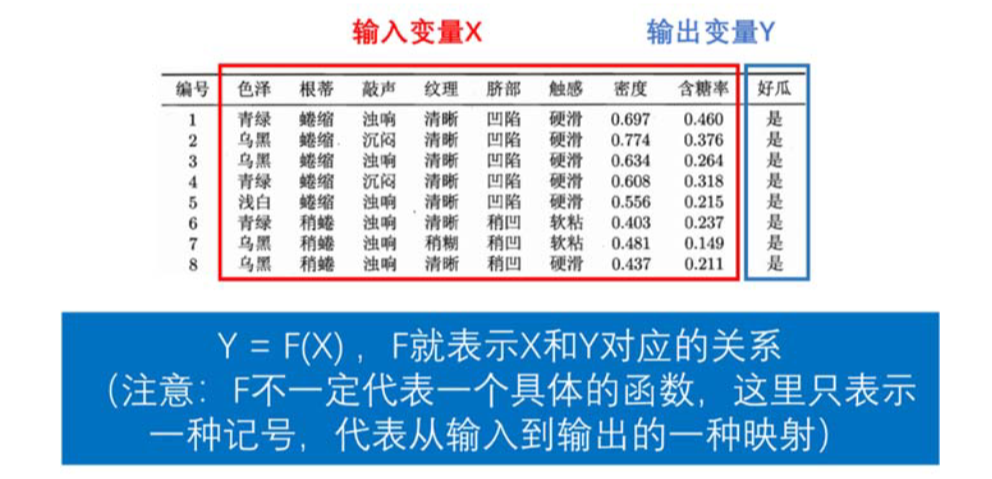
监督学习根据输出变量Y的数据类型不同,又可以分成两种类型:
(1) 当输出变量Y取有限个离散值时,称为分类问题。
举例:
判断西瓜的好坏(好瓜/坏瓜)
判断肿瘤的性质(良性/恶性)
根据鸢尾花的花萼长度、花萼宽度、花瓣长度和花瓣宽度这四个指标来判断它的种类(山鸢尾/杂色鸢尾/维吉尼亚鸢尾)
在分类问题中,当Y只取两类时,我们称为二分类问题,
当分类的类别为多个时, 称为多分类问题。
(2) 输出变量Y为连续型变量,称为回归问题。(此回归非彼回归)
举例:
给定房屋的一些信息(户型、是否靠近地铁等),预测房价
给定土地的施肥量,预测农作物的产量
无监督学习
无监督学习是指从无标注数据中学习预测模型的机器学习问题。无标注数据是自然得到的数据,预测模型表示数据的类别、转换或概率。无监督学习的本质是学习数据中的统计规律或潜在结构。
翻译成白话:我们的数据全部都是输入变量,没有输出变量。我们希望得到数据之间隐藏着的结构和规律。
无监督学习最常见的两种用法:聚类和降维。
聚类的例子:银行收集了客户的许多个人信息,根据这些个人信息可以将客户划 分到不同的用户群体(例如:贵宾客户、重点客户、普通客户、可能流失的客户等), 银行可以为不同的用户群体制定出相应的个性化营销方案。
降维的例子:输入变量的维度太大(指标个数太多了),我们需要通过降维的方法来构造出少数几个指标,这几个指标能保留原来这些输入变量的绝大部分信息。
注意:有很多同学区分不开聚类和分类的概念,事实上你只要知道监督学习和无监督学习的核心区别就行了(有无输出变量Y)。
在分类中,类别是已知的;而在聚类中,类别是不知道的,我们是通过数据的特征属性将数据划分到某几类中,这几个类代表的含义需要我们自己根据聚类的结果来定义。
半监督学习
数据有:输入变量X和部分输入变量的输出Y
强化学习
书中的定义:强化学习(reinforcement learning)是指智能系统在与环境的连 续互动中学习最优行为策略的机器学习问题。假设智能系统与环境的互动基于马尔可 夫决策过程(Markov decision process),智能系统能观测到的是与环境互动得到的 数据序列。强化学习的本质是学习最优的序贯决策。
举个例子:如何让电脑玩游戏?以 flappy bird 这款游戏为 例,电脑怎么知道下一步小鸟要采取怎样的行动呢? 通过不断与环境的交互和试错的过程,最终完成特定目的或使得整体行动收益最大化。(做对了给奖励,做错了给惩罚)
模型评估的指标(监督学习)
回归问题的评估指标



分类问题的评估指标
混淆矩阵——可以使用matlab自动生成
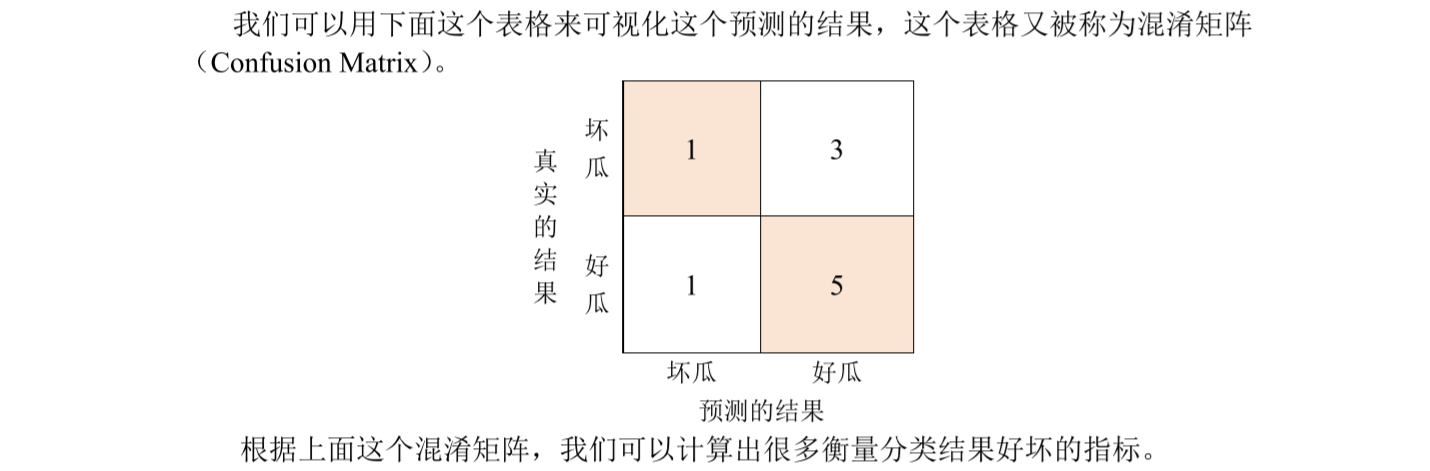
在此之前,我们需要定义分类结果中的正类(positive)和负类(negative),这里 的正类和负类实际上借用了医学中的阳性(positive)和阴性(negative)的概念,医学 中一般阴性代表正常,而阳性则代表患有疾病。
在机器学习中,我们通常将更关注的事件定义为正类事件。(生活中我们通常会更关注那些结果不好的情况的出现)
例如上面的西瓜分类的例子中,如果我们更关注坏瓜,就定义坏瓜为正类,好瓜为负类。(有些地方也用 0 和 1 表示分类结果,一般正类记为 1,负类记为 0)。
这种划分正类和负类的标准也不是绝对的,如果你更关注好瓜,那么你也可以把好瓜定义成正类;另外有 时候我们很难去区分结果的好坏,例如我们要对猫和狗的图片进行分类,这时候正类和负类无论怎么定义都行。

分类准确率,如果样本不平衡,计算出的结果回存在问题,因此这个指标本身存在问题
后两个指标,R和P更重要

通常来说,查全率和查准率是负相关关系的。
怎么理解查全率和查准率的关系:(知乎:李韶华的回答)
假设我们的目的是要找到人群中隐藏的坏人(把坏人当成正类)。 如果看重查全率R: 宁可错杀一千个好人,不可漏过一个坏人。(全部识别成坏人
时查全率为1)如果看重查准率 P: 宁可漏过坏人,不可错杀无辜的好人。(让 FP 尽量小一点,没有充足的证据不会轻易判断一个人是坏人)
查全率和查准率的调和平均

ROC曲线和AUC


模型的泛化能力
模型的泛化能力(generalization ability)是指由该模型对未知数据的预测能力。
过拟合问题!
留出法
我们需要想一个办法,只使 用已有的样本数据来对模型的泛化能力进行一个评价。
实际上这个办法很容易想到:还是假设我们现在有 100 个西瓜的数据,这些西瓜 的特征数据X以及是否为好瓜Y我们是知道的。
我们只拿出 80 个西瓜来训练我们的“西瓜分类器”,剩下的 20 个西瓜我们假装 不知道它们是好瓜还是坏瓜。接下来,我们把这 20 个西瓜的 X 输入到我们的“西瓜 分类器”中,来得到预测结果,并和这 20 个西瓜的真实类别进行对比来计算分类准
确率,这个结果就能反映模型的泛化能力的好坏。
我们将这里的 80 个西瓜称为训练 集(train set),它们用来训练我们的模型,得到我们模型中的待估参数;
剩下的 20 个 西瓜我们不参与模型的训练过程,只用来最后对模型的好坏进行测试,因此被称为**测试集(test set)**。
我们将上面这种对泛化能力进行评估的方法称为留出法(Hold-Out)。
(1) 假设我们总共的样本量为N,我们要将其划分为训练集和测试集,这两个集合的划分比例通常设置为:6:4、7:3 或 8:2。
(2) 训练集和测试集的划分既要随机,又要尽可能保持数据分布的一致性(在分类问题中就是类别比例的相似),例如原来 100 个瓜中有 60 个好瓜,40 个坏瓜,那么你按照 8:2 的比例生成训练集和测试集时,尽量保证测试集中的 20 个样本内有 12 个好瓜和 8 个坏瓜。在分类任务中,保留类别比例
的采样方法称为分层采样(stratified sampling)。
留出法的缺陷:在留出法中,用于评价模型泛化能力的测试集只是所有样本的一部分,而且这个 结果不是很稳定,对模型的泛化能力的评价依赖于哪些样本点落入训练集,哪些样本点在测试集。
交叉验证
下面我们介绍一种用的更多的方法:k 折交叉验证(K-fold cross-validation)。
我们先将数据集D随机的划分为 k 个大小相似的互斥子集。
每一次用 k-1 个子集 的并集作为训练集,剩下的一个子集作为测试集;
这样就可以获得 k 组训练/测试集, 从而可进行 k 次训练和测试,最终返回的是这 k 次测试的平均结果,通常 k 取 10,此时称为 10 折交叉验证。

选择最好的模型
我们可以使用决策树、K 最近邻(KNN)、支持向量机(SVM)等常用的机器 学习模型。那么,我们应该怎样衡量一个模型的好坏呢?
我们前面介绍了留出法和交叉验证法,这里面都需要将数据分成训练集和测试集。 因此,我们可以在同一个训练集下,分别对这些模型进行训练,然后将这些模型分别 在测试集上进行预测,并比较不同模型的泛化能力,我们选择泛化能力最好的模型。
(该模型在测试集上的表现最好,例如误差最小,具体的评价指标在前面有介绍)另外,大多数的模型中都需要设定一些参数(parameter),参数不同得到的结果可 能有很明显的差异。因此,除了要对模型进行选择外,还需要对模型中的参数进行设 定,这就是机器学习中常说的“参数调节”或简称“调参”(parameter tuning)。通常调
参依赖于经验,我们后面会介绍网格搜索的方法,来自动搜索使模型效果最好的参数。
1 | |
欠拟合和过拟合
过拟合(overfitting)指的是模型在训练集上表现的很好,但是在测试集上表现的并不理想,也就是说模型对未知样本的预测表现一般,泛化能力较差。
如果模型不仅在训练数据集上的预测结果不好,而且在测试数据集上的表现也不理想,也就是说两者的表现都很糟糕,那么我们有理由怀疑模型发生了欠拟合(underfitting)现象。


可能产生过拟合的常见原因:
(1) 模型中参数设置的过多导致模型过于复杂 ;
(2) 训练集的样本量不够 ;
(3) 输入了某些完全错误的的特征
举个极端的例子:样本的编号。现在有 100 个西瓜,编号 1-60 的是好瓜, 编号 61-100 的是坏瓜,如果你把编号作为了输入变量放入了我们的模型, 那么有可能模型会将编号作为一个最重要的识别变量来对西瓜进行分类, 模型会认为只要编号小于等于 60 的都是好瓜,此时在训练集上的误差一 定为 0。。。。。。如果这时候你拿来编号大于 100 的需要判断好坏的瓜,模型 都会认为是坏瓜!
解决过拟合的方法:
(1) 通过前面介绍的交叉验证的方法来选择合适的模型,并对参数进行调节。
(2) 扩大样本数量、训练更多的数据
(3) 对模型中的参数增加正则化(即增加惩罚项,参数越多惩罚越大)
欠拟合则和过拟合刚好相反,我们可以增加模型的参数、或者选择更加复杂的模 型;也可以从数据中挖掘更多的特征来增加输入的变量,还可以使用一些集成算法(如 装袋法(Bagging),提升法(Boosting))。
(注意:有可能模型的输入和输出一点关系都没有,举个极端的例子,你买的西 瓜好坏和你的个人特征没任何关系,例如你的性别身高体重等)
常见的机器学习算法的思想
K最近邻(KNN)
决策树(Decision Tree)
支持向量机(SVM)
线性支持向量机
非线性支持向量机
集成学习(ensemble learning)
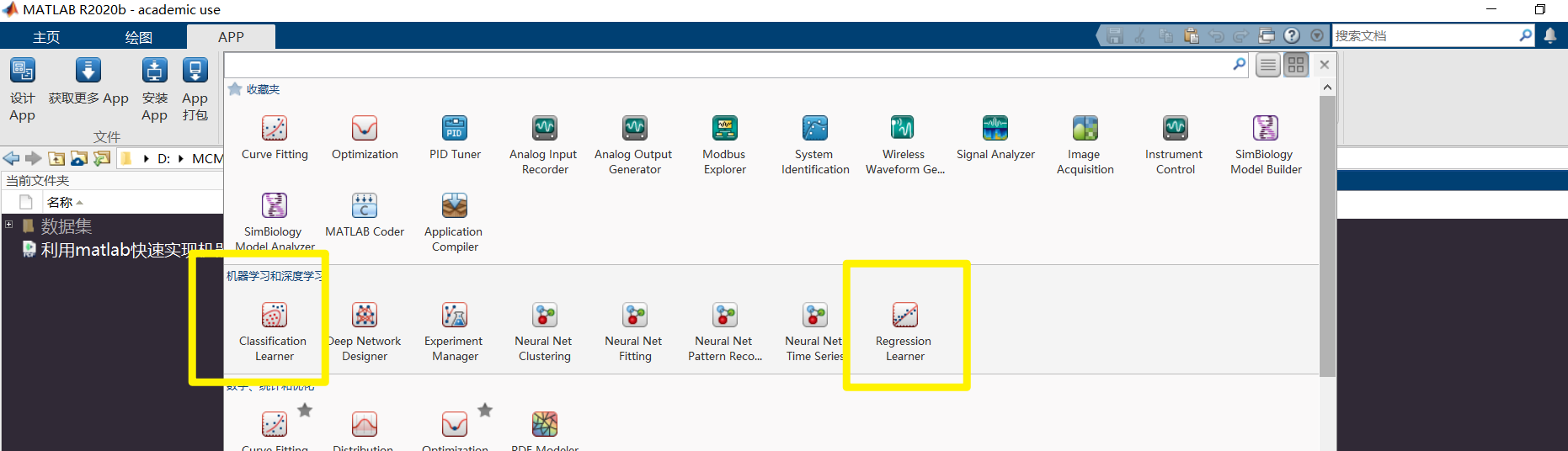
Matlab中机器学习的应用

蒙特卡洛

引例:布丰投针
通过针与平行线中任意一条相交的概论,计算pi
axis:绘制坐标在的框架
蒙特卡洛概述
蒙特卡洛方法又称统计模拟法,是一种随机模拟方法,以概率论和数理统计方法为基础的一种计算方法,是使用随机数来解决很多计算问题的方法。
原理:由大数定理可知,当样本容量足够大的时候,事件的发生频率即其概率
蒙特卡洛不是一种算法,而是一种方法,蒙特卡洛没有固定的通用代码。
蒙特卡洛是枚举的一种变异
应用1 三门问题
三门问题(Monty Hall problem)亦称为蒙提霍尔问题、蒙特霍问题或蒙提霍尔悖论,大致出自美国的电视游戏节目Let’s Make a Deal。问题名字来自该节目的主持人蒙提·霍尔(Monty Hall)。参赛者会看见三扇关闭了的门,其中一扇的后面有一辆汽车,选中后面有车的那扇门可赢得该汽车,另外两扇门后面则各藏有一只山羊。当参赛者选定了一扇门,但未去开启它的时候,节目主持人开启剩下两扇门的其中一扇,露出其中一只山羊。主持人其后会问参赛者要不要换另一扇仍然关上的门。问题是:换另一扇门是否会增加参赛者赢得汽车的机率。如果严格按照上述的条件,那么答案是会。不换门的话,赢得汽车的几率是1/3。换门的话,赢得汽车的几率是2/3。
虽然该问题的答案在逻辑上并不自相矛盾,但十分违反直觉。这问题曾引起一阵热烈的讨论。
李永乐,三门问题
应用2 模拟排队问题
指数分布

1 | |
应用3 有约束的非线性规划问题

非线性规划——局部最优解,计算时需要初始值
全局最优解是计算不出来的!
把约束条件使用放缩法,计算出每个变量的取值范围
format long g——计算出的结果,显示更多的小数位数
x=unifrnd(20,30,n,1):生成[20,30]之间均匀分布的随即数组成的n行1列的向量构成x
应用4 01规划问题
unique函数:剔除一个矩阵或者向量的重复值,并将结果按照从小到大的顺序排列
循环进行超级多次,得到最优解
应用5 导弹追踪问题
连续的时间离散化
mod(8,3):求余数
应用6 旅行商问题(TSP)
n数值过大的时候,可能出现的次数将达到非常大的量级
randperm函数:随即序列
http://www.math.uwaterloo.ca/tsp/
数学规划模型
数学规划:数学规划三运筹学的一个分支,期用来研究:在给定的条件下(约束条件),如何按照某一衡量指标(目标函数)来寻求计划,管理工作中的最优方案,即求目标函数在一定约束条件下的极值问题!
数学规划的一般形式

概念
数学规划的分类
线性规划
目标函数和约束条件是决策变量的线性表达式
单纯形法非线性规划
目标函数或者约束条件是决策变量的非线性表达式
没有通用算法,大多数算法都是选定决策变量的初始值之后,通过一定的搜索方法,寻找最优的决策变量整数规划
要求变量取整数的数学规划,分为线性整数规划和非线性整数规划
求解线性整数规划问题能求解
非线性整数规划——蒙特卡洛模拟0-1 规划
重点内容
线性规划问题的求解——matlab
Matlab中线性规划的标准型

matlab中求解线性规划的命令
[x,fval] = linprog[C,A,b,Aeg,beg,lb,ub,x0]
1 | |

典型例题
- 生产决策问题
- 投料问题
整数规划

Matlab 整数规划求解
[x,fval] = intlinprog[C,intcon,A,b,Aeg,beg,lb,ub]
注:
- intlinprog不能指定初始值
- intcon参数可以指定那些决策变量是整数
Matlab 线性0-1规划求解,仍然使用intlinprog函数,只不过是在lb和ub上作文章
整数规划的例题
- 背包问题
- 指派问题
- 钢管切割问题
Matlab中的非线性规划的标准型

非线性规划求解的函数
[x,fval] = fmincon(@fun,x0,A,b,Aeq,beq,lb,up,@nonlfun,option)



非线性规划的例题:
- 选址问题
- 飞行管理问题
最大最小化模型


多目标规划模型
